직접적인 퍼지 논리적 추론. 주제에 대한 실험실 작업 지침: "퍼지 추론 퍼지 추론 시스템 학습
퍼지 집합과 퍼지 논리의 수학 이론은 고전 집합 이론과 고전 형식 논리의 일반화입니다. 이 개념은 1965년 미국 과학자 Lotfi Zadeh에 의해 처음 제안되었습니다. 새로운 이론이 등장한 주된 이유는 사람이 프로세스, 시스템, 대상을 설명할 때 모호하고 대략적인 추론이 있었기 때문입니다.
복잡한 시스템을 모델링하는 퍼지 접근 방식이 전 세계적으로 인정되기 전에 퍼지 집합 이론이 탄생한 지 10년 이상이 지났습니다. 그리고 퍼지 시스템 개발의이 경로에서 세 기간을 구별하는 것이 일반적입니다.
첫 번째 기간(60년대 후반-70년대 초반)은 퍼지 집합의 이론적 장치(L. Zadeh, E. Mamdani, Bellman)의 개발이 특징입니다. 두 번째 기간(70~80년대)에는 복잡한 기술 시스템(퍼지 제어 증기 발생기)의 퍼지 제어 분야에서 첫 번째 실제 결과가 나타납니다. 동시에 퍼지 논리에 기반한 전문가 시스템 구축 문제, 퍼지 컨트롤러의 개발 문제에 주목하기 시작했습니다. 의사결정 지원을 위한 퍼지 전문가 시스템은 의학 및 경제 분야에서 널리 사용됩니다. 마지막으로 80년대 후반부터 현재까지 이어지는 3기에는 퍼지 전문가 시스템을 구축하기 위한 소프트웨어 패키지가 등장하며 퍼지 논리의 적용 영역이 눈에 띄게 확대되고 있다. 자동차, 항공 우주 및 운송 산업, 가전 제품 분야, 금융, 분석 및 관리 의사 결정 분야 및 기타 여러 분야에서 사용됩니다.
80년대 후반 Bartholomew Kosko의 증명 이후에 시작된 세계 퍼지 논리의 승리 행진 유명한 정리 FAT(퍼지 근사 정리). 비즈니스와 금융에서 퍼지 논리는 1988년에 금융 지표를 예측하는 퍼지 규칙 기반 전문가 시스템이 주식 시장 붕괴를 예측하는 유일한 시스템이었을 때 인정을 받았습니다. 그리고 성공적인 퍼지 애플리케이션의 수는 이제 수천에 달합니다.
수학 장치
퍼지 집합의 특징은 멤버십 함수입니다. MF c(x)로 표시하는 퍼지 집합 C의 소속 정도는 일반 집합의 특성 함수 개념을 일반화한 것입니다. 그런 다음 퍼지 집합 C는 C=(MF c(x)/x), MF c(x) 형식의 순서쌍 집합입니다. 값 MF c(x)=0은 집합에 구성원이 없음, 1 – 전체 구성원을 의미합니다.
간단한 예를 들어 설명하겠습니다. 우리는 "뜨거운 차"의 부정확한 정의를 공식화합니다. x(추론 영역)는 섭씨 온도 단위가 됩니다. 분명히 0도에서 100도까지 변경됩니다. "뜨거운 차" 개념에 대한 퍼지 세트는 다음과 같습니다.
C=(0/0; 0/10; 0/20; 0.15/30; 0.30/40; 0.60/50; 0.80/60; 0.90/70; 1/80; 1/90; 1/100).
따라서 온도가 60C인 차는 회원 등급이 0.80인 "뜨거운" 세트에 속합니다. 어떤 사람에게는 60C의 온도에서 차가 뜨거울 수 있고 다른 사람에게는 너무 뜨겁지 않을 수 있습니다. 이에 상응하는 집합 할당의 모호함이 나타납니다.
퍼지 집합과 일반 집합의 경우 주요 논리 연산이 정의됩니다. 계산에 필요한 가장 기본적인 것은 교집합과 합집합이다.
두 퍼지 집합의 교집합(퍼지 "AND"): A B: MF AB(x)=min(MF A(x), MF B(x)).
두 퍼지 집합의 합집합(퍼지 "OR"): A B: MF AB(x)=max(MF A(x), MF B(x)).
퍼지 집합 이론에서 교차, 합집합 및 덧셈 연산자의 실행에 대한 일반적인 접근 방식이 개발되어 소위 삼각형 놈 및 뿔로 구현되었습니다. 위의 교차 및 합집합 연산의 구현은 t-norm 및 t-conorm의 가장 일반적인 경우입니다.
퍼지 집합을 설명하기 위해 퍼지 및 언어 변수의 개념이 소개됩니다.
퍼지 변수는 집합 (N,X,A)로 설명됩니다. 여기서 N은 변수의 이름, X는 보편적 집합(추론 영역), A는 X에 대한 퍼지 집합입니다.
언어 변수의 값은 퍼지 변수가 될 수 있습니다. 언어 변수는 퍼지 변수보다 높은 수준에 있습니다. 각 언어 변수는 다음으로 구성됩니다.
- 제목;
- 기본 용어 집합 T라고도 하는 값의 집합입니다. 기본 용어 집합의 요소는 퍼지 변수의 이름입니다.
- 유니버설 세트 X;
- 자연어 또는 형식어의 단어를 사용하여 새로운 용어가 생성되는 구문 규칙 G;
- 언어 변수의 각 값을 집합 X의 퍼지 부분 집합과 연결하는 의미 규칙 P.
"주식 가격"과 같은 모호한 개념을 고려하십시오. 이것은 언어 변수의 이름입니다. "낮음", "보통", "높음"의 세 가지 퍼지 변수로 구성되고 추론 영역을 X=(단위) 형식으로 설정하는 기본 용어 집합을 구성해 보겠습니다. 마지막으로 해야 할 일은 기본 용어 집합 T에서 각 언어 용어에 대한 소속 함수를 구축하는 것입니다.
멤버십 함수를 정의하기 위한 12가지 이상의 일반적인 곡선 모양이 있습니다. 가장 널리 사용되는 것은 삼각형, 사다리꼴 및 가우스 멤버십 함수입니다.
삼각형 소속 함수는 세 개의 숫자(a,b,c)로 정의되며 점 x에서의 값은 다음 식에 따라 계산됩니다.
$$MF\,(x) = \,\begin(케이스) \;1\,-\,\frac(b\,-\,x)(b\,-\,a),\,a\leq \,x\leq \,b &\ \\ 1\,-\,\frac(x\,-\,b)(c\,-\,b),\,b\leq \,x\leq \ ,c &\ \\ 0, \;x\,\in\이 아님,(a;\,c)\ \end(cases)$$
(b-a)=(c-b)를 사용하면 삼중(a,b,c)의 두 매개변수로 고유하게 지정할 수 있는 대칭 삼각형 소속 함수의 경우가 있습니다.
마찬가지로 사다리꼴 소속 함수를 설정하려면 네 개의 숫자(a, b, c, d)가 필요합니다.
$$MF\,(x)\,=\, \begin(케이스) \;1\,-\,\frac(b\,-\,x)(b\,-\,a),\,a \leq \,x\leq \,b & \\ 1,\,b\leq \,x\leq \,c & \\ 1\,-\,\frac(x\,-\,c)(d \,-\,c),\,c\leq \,x\leq \,d &\\ 0, x\,\not \in\,(a;\,d) \ \end(cases)$$
(b-a)=(d-c)에서 사다리꼴 소속 함수는 대칭 형태를 취합니다.
가우스 유형의 소속 함수는 다음 공식으로 설명됩니다.
$$MF\,(x) = \exp\biggl[ -\,(\Bigl(\frac(x\,-\,c)(\sigma)\Bigr))^2\biggr]$$
두 개의 매개변수에서 작동합니다. 매개변수 씨퍼지 집합의 중심을 나타내며 매개변수는 함수의 기울기를 담당합니다.

기본 항 집합 T의 각 항에 대한 소속 함수 집합은 일반적으로 하나의 그래프에 함께 표시됩니다. 그림 3은 위에서 설명한 언어적 변수 "주가"의 예를 보여주고, 그림 4는 "사람의 나이"라는 부정확한 개념의 공식화를 보여준다. 따라서 48 세 사람의 경우 "젊음"세트에 속하는 정도는 0, "평균"- 0.47, "평균 이상"- 0.20입니다.
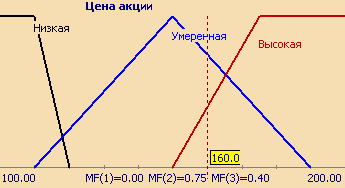

언어 변수의 용어 수가 7을 초과하는 경우는 거의 없습니다.
퍼지 추론
퍼지 추론 작업을 수행하기 위한 기초는 "If-then" 형식의 퍼지 문과 해당 언어 용어에 대한 소속 함수를 포함하는 규칙 기반입니다. 이 경우 다음 조건이 충족되어야 합니다.
- 출력 변수의 각 언어 용어에 대해 하나 이상의 규칙이 있습니다.
- 입력 변수의 모든 항에 대해 이 항이 전제 조건으로 사용되는 규칙이 하나 이상 있습니다(규칙의 왼쪽).
그렇지 않으면 퍼지 규칙의 불완전한 기반이 있습니다.
규칙 기반에 다음 형식의 m 규칙이 있습니다.
R 1: IF x 1은 A 11 ... AND ... x n은 A 1n THEN y는 B 1
…
R i: IF x 1 is A i1 ... AND ... x n is A in THEN y is B i
…
R m: IF x 1 은 A i1 ... AND ... x n 은 A mn THEN y 는 B m ,
여기서 x k , k=1..n – 입력 변수; y는 출력 변수입니다. Aik에는 멤버십 함수가 포함된 퍼지 세트가 제공됩니다.
퍼지 추론의 결과는 주어진 선명한 값 x k , k=1..n 에 기반한 변수 y * 의 선명한 값입니다.
일반적으로 추론 메커니즘은 퍼지 도입(퍼지화), 퍼지 추론, 구성 및 명료도로 축소, 또는 비퍼지화의 4단계로 구성됩니다(그림 5 참조).

퍼지 추론 알고리즘은 주로 사용되는 규칙의 유형, 논리 연산 및 역퍼지화 방법의 유형이 다릅니다. Mamdani, Sugeno, Larsen, Tsukamoto 퍼지 추론 모델이 개발되었습니다.
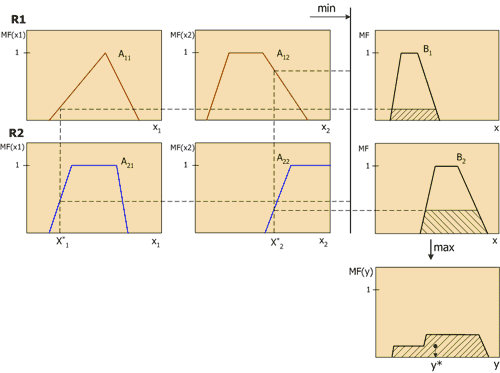
Mamdani 메커니즘을 예로 들어 퍼지 추론을 더 자세히 살펴보겠습니다. 이것은 퍼지 시스템에서 가장 일반적인 논리적 추론 방법입니다. 퍼지 집합의 최소 구성을 사용합니다. 이 메커니즘에는 다음과 같은 일련의 작업이 포함됩니다.
- 퍼지화 절차: 진실의 정도가 결정됩니다. 각 규칙의 왼쪽 부분에 대한 멤버십 함수의 값(필수 조건). m개의 규칙이 있는 규칙 기반의 경우 A ik(x k), i=1..m, k=1..n으로 진실의 정도를 나타냅니다.
애매한 결론. 먼저 각 규칙의 왼쪽에 대한 "컷오프" 수준이 결정됩니다.
$$alfa_i\,=\,\min_i \,(A_(ik)\,(x_k))$$
$$B_i^*(y)= \min_i \,(alfa_i,\,B_i\,(y))$$
퍼지 집합의 최대 구성이 사용되는 구성 또는 얻은 잘린 함수의 합집합:
$$MF\,(y)= \max_i \,(B_i^*\,(y))$$
여기서 MF(y)는 결과 퍼지 집합의 소속 함수입니다.
Defuzzification, 또는 명료도로의 감소. 여러 가지 역퍼지화 방법이 있습니다. 예를 들어, 평균 중심 방법 또는 중심 방법은 다음과 같습니다.
$$MF\,(y)= \max_i \,(B_i^*\,(y))$$
이 값의 기하학적 의미는 MF(y) 곡선의 무게 중심입니다. 그림 6은 두 개의 입력 변수와 두 개의 퍼지 규칙 R1 및 R2에 대한 Mamdani 퍼지 추론 프로세스를 그래픽으로 보여줍니다.
지능형 패러다임과의 통합
90년대를 지나면서 서구와 미국 연구자들의 모토는 지적 정보 처리 방식의 혼성화다. 여러 기술을 결합한 결과 인공 지능 1994년 L. Zadeh가 도입한 "소프트 컴퓨팅"(소프트 컴퓨팅)이라는 특수 용어가 등장했습니다. 현재 소프트 컴퓨팅은 퍼지 논리, 인공 신경망, 확률 추론 및 진화 알고리즘과 같은 영역을 결합합니다. 이들은 서로를 보완하고 다양한 조합으로 사용되어 하이브리드 지능형 시스템을 생성합니다.
퍼지 논리의 영향은 아마도 가장 광범위한 것으로 판명되었습니다. 퍼지 집합이 고전적 수학적 집합 이론의 범위를 확장한 것처럼 퍼지 논리는 거의 대부분의 데이터 마이닝 방법을 "침략"하여 새로운 기능을 부여했습니다. 그러한 연관성의 가장 흥미로운 예가 아래에 나와 있습니다.
퍼지 신경망
퍼지 신경망(fuzzy-neural network)은 퍼지 논리 장치를 기반으로 결론을 수행하지만 구성원 함수의 매개변수는 NN 학습 알고리즘을 사용하여 조정됩니다. 따라서 이러한 네트워크의 매개 변수를 선택하기 위해 원래 다층 퍼셉트론 학습을 위해 제안된 역전파 방법을 사용합니다. 이를 위해 퍼지 제어 모듈은 다계층 네트워크 형태로 제시된다. 퍼지 신경망은 일반적으로 입력 변수를 위한 퍼지화 계층, 조건 활성화 값을 집계하는 계층, 퍼지 규칙을 집계하는 계층 및 출력 계층의 4개 계층으로 구성됩니다.
ANFIS 및 TSK 유형의 퍼지 신경망 아키텍처가 현재 가장 널리 사용됩니다. 그러한 네트워크는 보편적인 근사치라는 것이 증명되었습니다.
빠른 학습 알고리즘과 축적된 지식의 해석 가능성 - 이러한 요소는 오늘날 퍼지 신경망을 소프트 컴퓨팅을 위한 가장 유망하고 효과적인 도구 중 하나로 만들었습니다.
적응형 퍼지 시스템
고전적인 퍼지 시스템은 규칙과 회원 기능을 공식화하기 위해 항상 제공할 수 없는 특정 주제 영역의 전문가를 참여시켜야 한다는 단점이 있습니다. 적응형 퍼지 시스템은 이 문제를 해결합니다. 이러한 시스템에서 퍼지 시스템 매개변수는 실험 데이터에 대한 학습 과정에서 선택됩니다. 적응형 퍼지 시스템 학습을 위한 알고리즘은 신경망 학습 알고리즘에 비해 상대적으로 시간이 많이 걸리고 복잡하며, 일반적으로 두 단계로 구성됩니다. 1. 언어 규칙 생성; 2. 회원 기능의 수정. 첫 번째 문제는 열거형 문제와 관련이 있고 두 번째 문제는 연속 공간에서의 최적화와 관련이 있습니다. 이 경우 퍼지 규칙을 생성하려면 멤버십 함수가 필요하고 퍼지 추론을 수행하려면 규칙이 필요하다는 모순이 발생합니다. 또한 퍼지 규칙을 자동으로 생성할 때 완전성과 일관성을 보장해야 합니다.
퍼지 시스템 훈련 방법의 상당 부분은 유전 알고리즘을 사용합니다. 영문학에서 이것은 특수 용어인 Genetic Fuzzy Systems에 해당합니다.
F. Herrera가 이끄는 스페인 연구원 그룹은 진화적 적응을 통해 퍼지 시스템의 이론과 실제 개발에 상당한 기여를 했습니다.
퍼지 쿼리
퍼지 데이터베이스 쿼리는 현대 정보 처리 시스템에서 유망한 방향입니다. 이 도구를 사용하면 자연 언어로 쿼리를 공식화할 수 있습니다. 예를 들어 "도심과 가까운 저렴한 주택 제안 목록 표시"는 표준 쿼리 메커니즘으로는 불가능합니다. 이를 위해 퍼지 관계 대수 및 퍼지 쿼리를 위한 SQL 언어의 특수 확장이 개발되었습니다. 이 분야의 연구 대부분은 서유럽 과학자 D. Dubois와 G. Prade에 속합니다.
퍼지 연관 규칙
퍼지 연관 규칙은 언어 문장으로 공식화된 데이터베이스에서 패턴을 추출하기 위한 도구입니다. 여기에서는 퍼지 트랜잭션의 특별한 개념, 퍼지 연관 규칙의 지원 및 신뢰성을 소개합니다.
퍼지 인지 맵
퍼지 인지 지도는 1986년 B. Kosko에 의해 제안되었으며 특정 영역의 개념 간에 식별된 인과 관계를 모델링하는 데 사용됩니다. 단순 인지 맵과 달리 퍼지 인지 맵은 노드가 퍼지 집합인 퍼지 방향 그래프입니다. 그래프의 방향 모서리는 개념 간의 인과 관계를 반영할 뿐만 아니라 연관된 개념의 영향(가중치) 정도를 결정합니다. 퍼지 인지 맵을 시스템 모델링 도구로 적극적으로 사용하는 것은 분석된 시스템의 시각적 표현 가능성과 개념 간의 인과 관계 해석의 용이성 때문입니다. 주요 문제는 형식화를 수용할 수 없는 인지 맵을 구성하는 과정과 관련이 있습니다. 또한 구축된 인지지도가 실제 모의 시스템에 적합함을 증명할 필요가 있다. 이러한 문제를 해결하기 위해 데이터 샘플을 기반으로 인지도를 자동으로 구성하는 알고리즘이 개발되었습니다.
퍼지 클러스터링
퍼지 클러스터링 방법은 정밀 방법(예: Kohonen 신경망)과 달리 동일한 개체가 여러 클러스터에 동시에 속할 수 있지만 정도는 다릅니다. 많은 상황에서 퍼지 클러스터링은 예를 들어 클러스터 경계에 있는 개체의 경우 명확한 것보다 "자연적"입니다. 가장 일반적인 것은 c-means fuzzy self-organization algorithm과 Gustafson-Kessel 알고리즘 형태의 일반화입니다.
문학
- Zadeh L. 언어 변수의 개념과 대략적인 결정을 내리기 위한 응용. – M.: Mir, 1976.
- Kruglov V.V., Dli M.I. 지능형 정보 시스템: 퍼지 논리 및 퍼지 추론 시스템을 위한 컴퓨터 지원. – M.: Fizmatlit, 2002.
- 레오렌코프 A.V. MATLAB 및 fuzzyTECH의 퍼지 모델링. - 상트페테르부르크, 2003.
- Rutkovskaya D., Pilinsky M., Rutkovsky L. 신경망, 유전 알고리즘 및 퍼지 시스템. - 엠., 2004.
- Masalovich A. 비즈니스 및 금융의 퍼지 논리. www.tora-centre.ru/library/fuzzy/fuzzy-.htm
- Kosko B. 범용 근사치로서의 퍼지 시스템 // IEEE Transactions on Computers, vol. 43, 아니. 1994년 11월 11일. - P. 1329-1333.
- Cordon O., Herrera F., 유전 퍼지 시스템에 대한 일반 연구 // 공학 및 컴퓨터 과학의 유전 알고리즘, 1995. - P. 33-57.
"전문가 시스템"분야의 실습 교육
학년도, 가을학기
Lesson 1. 프로덕션 시스템의 추론
실시예 1 . 두 가지 규칙의 지식 기반 조각이 있습니다.
P1: (휴식 - 여름) 및 (사람 - 활동) 경우
그럼 (산에 가려고)
P2: 만약 (사랑 - 태양)
그런 다음 (방학 - 여름)
시스템이 (사람 - 활동) 및 (사랑 - 태양) 데이터를 수신했다고 가정합니다.
직접 철수 - 데이터를 바탕으로 답을 얻습니다.
1차 통과.
1단계. P1을 시도했지만 작동하지 않습니다(데이터 누락(여름 방학)).
2단계. P2를 시도하면 작동하고 사실(여름 휴가)이 데이터베이스에 입력됩니다.
2차 패스.
3 단계. 우리는 P1을 시도하고 작동하며 목표가 활성화되어 (산으로 가기 위해) 결론으로 작용합니다.
역출력 - 사용 가능한 규칙 및 데이터를 사용하여 선택한 대상을 확인합니다.
1차 통과.
1 단계. 목표 - (산에 가기 위해) : 우리는 P1을 시도합니다 - 데이터가없고 (휴식 - 여름) 새로운 목표가되고 규칙이 오른쪽에서 검색됩니다.
2단계. 목표(휴식 - 여름): R2 규칙은 목표를 확인하고 활성화합니다.
2차 패스.
3단계. P1을 시도하면 원하는 목표가 확인됩니다.
실시예 2 BZ ES는 증권 거래소의 상태를 나타냅니다.
· 만약 금리떨어지다, 그 다음에 증권 거래소의 가격 수준이 상승하고 있습니다..
· 만약 금리가 오르고 있다, 그 다음에 증권 거래소의 가격 수준이 하락합니다..
· 만약 달러 환율 하락, 그 다음에 금리가 오르고 있다.
· 만약 달러 환율이 오르고 있다, 그 다음에 금리가 떨어지고 있다.
· 만약 연준 금리 하락 그리고 연방준비제도(Fed) 기금 추가, 그 다음에 금리가 떨어지고 있다.
달러 환율이 떨어지고 있습니다. 증권 거래소의 가격 수준을 결정합니다.
실시예 3 그림 1에 표시된 것을 사용하여 신입 사원을 고용할 때 이사에게 조언하는 전문가 시스템의 지식 기반에 대한 규칙을 개발하십시오. 1 시맨틱 웹. 네트워크의 꼭짓점은 이벤트 발생에 대한 신뢰 계수를 나타냅니다.
실시예 4 지정된 기준과 목표를 사용하여 아파트를 구입할 때 클라이언트에게 조언하는 전문가 시스템의 지식 기반에 대한 규칙을 개발합니다.
기준:집 건설 날짜; 주택 상태(수리 필요); 아파트가 위치한 지역; 지역의 생태적 상황; 대중 교통 정류장에서 거리; 아파트 비용.
목표:아파트는 훌륭하고 당신을 완전히 만족시킵니다. 아파트는 여러 가지 단점이 있지만 만족스럽습니다. 아파트는 당신에게 어울리지 않습니다.
실시예 5 지정된 기준과 목표를 사용하여 자동차를 구입할 때 고객에게 조언하는 전문가 시스템의 지식 기반에 대한 의사 결정 트리를 개발합니다.
기준:자동차 브랜드(예: VAZ, Audi, BMW, Renault, Subaru, Honda), 제조 연도, 가격, 기어 수, 엔진 크기, 도어 수, 연료 소비.
목표:자동차 선택.
Lesson 2. 퍼지 집합 이론을 이용한 지식 처리
옵션 1
예제 1. 퍼지 추론 시스템(FIS) 개발
할인율 및 투자회수 기간에 대한 데이터를 기반으로 특정 비즈니스 프로젝트의 투자 매력도를 평가할 필요가 있습니다. 문제 해결은 다음 단계로 구성됩니다.
스테이지 1. START 구조를 만들어 보겠습니다. 두 개의 입력, Mamdani 퍼지 추론 메커니즘, 하나의 출력. 첫 번째 변수를 다음과 같이 선언합니다. 할인, 그리고초 - 기간,이는 각각 비즈니스 프로젝트의 할인율과 투자 회수 기간을 나타냅니다. 사업 프로젝트의 투자 매력도를 판단하는 기준이 되는 산출변수의 명칭은 다음과 같다. 비율.
2단계.각 입력 및 출력 변수에는 일련의 멤버십 함수(FC)가 할당됩니다. 을위한 할인기본 변수의 범위를 5에서 50까지 정의합니다(측정 단위 - 백분율). 디스플레이에 대해 동일한 범위를 선택합니다. 삼각형 퍼지 숫자(trimf) 유형인 세 개의 FP를 추가해 보겠습니다. 언어 변수 "할인율"의 경우 할인"작은", "중간"및 "대"라는 용어의 값을 정의하십시오 ( 소형, 중형, 대형).
언어 변수의 경우 기간기본 변수의 범위는 "짧은", "보통", "긴" 투자 회수 기간(s 짧은, 보통, 긴)가우스 유형의 세 FP (가우스mf). 출력 변수 비율에 대해 다음을 정의합니다. 기본 변수의 범위는 "나쁨", "보통", "좋음"(나쁨, 보통, 좋음)이라는 용어가 유형의 세 FP로 설명됩니다. 손질
3단계. 입력 변수와 출력 변수 간의 관계를 정의하는 IF…THEN 형식의 규칙 집합을 정의해 보겠습니다(직접 수행). 예를 들어, 규칙
만약 할인=소그리고 마침표가 짧은그 다음에 비율=좋다
4단계.전문가 시스템에 의한 추천 구성. 프로젝트의 투자 매력도를 결정하려고 한다고 가정합니다. 지식 기반의 규칙을 사용하기 위해서는 할인율과 투자 회수 기간에 대한 정보가 필요합니다.
작업: 나머지 할인에 대한 데이터를 사용하여 프로젝트의 투자 매력도를 결정합니다. 할인=15%,사업 프로젝트의 회수 기간 기간= 10개월.
퍼지 추론의 개념은 퍼지 논리와 퍼지 제어 이론의 핵심입니다. 제어 시스템의 퍼지 논리에 대해 말하면 퍼지 추론 시스템에 대해 다음과 같이 정의할 수 있습니다.
퍼지 추론 시스템객체의 현재 상태에 대한 정보인 퍼지 조건 또는 전제 조건을 기반으로 객체에 필요한 제어에 대한 퍼지 결론을 얻는 과정입니다.
이 프로세스는 퍼지 집합 이론의 모든 기본 개념(멤버십 함수, 언어 변수, 퍼지 함축 방법 등)을 결합합니다. 퍼지 추론 시스템의 개발 및 적용에는 여러 단계가 포함되며, 그 구현은 앞서 고려한 퍼지 논리 조항을 기반으로 수행됩니다(그림 2.18).
그림 2.18. 퍼지 ACS의 퍼지 추론 프로세스 다이어그램
퍼지 추론 시스템의 규칙 기반은 형식적으로 특정 주제 영역의 전문가의 경험적 지식을 표현하도록 설계되었습니다. 퍼지 생산 규칙.따라서 퍼지 추론 시스템의 퍼지 생성 규칙의 기본은 다양한 상황에서 객체를 관리하는 방법, 다양한 조건에서의 기능 특성 등에 대한 전문가의 지식을 반영하는 퍼지 생성 규칙 시스템입니다. 형식화된 인간 지식을 포함합니다.
퍼지 생성 규칙다음 형식의 표현입니다.
(i):Q;P;A═>B;S,F,N,
여기서 (i)는 퍼지 생산의 이름, Q는 퍼지 생산의 범위, P는 퍼지 생산의 핵심에 대한 적용 조건, A═>B는 퍼지 생산의 핵심입니다. 여기서 A는 핵심(또는 선행)의 조건, B는 핵심(또는 후건)의 결론, ═>는 논리적 시퀀스 또는 후속의 기호, S는 진리도의 정량적 값을 결정하는 방법 또는 방법 핵심 결론, F는 퍼지 생산의 확실성 또는 신뢰도 계수, N은 생산 사후 조건입니다.
퍼지 제품의 범위 Q는 별도의 제품이 나타내는 지식의 주제 영역을 명시적 또는 묵시적으로 기술합니다.
프로덕션 커널 P의 적용 가능성 조건은 일반적으로 술어인 논리식입니다. 프로덕션에 존재하는 경우 이 조건이 true인 경우에만 프로덕션 코어의 활성화가 가능해집니다. 많은 경우 이 제품 요소는 생략되거나 제품의 핵심에 도입될 수 있습니다.
커널 A═>B는 퍼지 생성의 핵심 구성 요소입니다. 더 일반적인 형식 중 하나로 제시될 수 있습니다. "IF A THEN B", "IF A THEN B"; 여기서 A와 B는 퍼지 논리의 일부 표현으로, 가장 자주 퍼지 명령문의 형태로 표현됩니다. 복합 논리적 퍼지 문은 표현식으로도 사용할 수 있습니다. 퍼지 부정, 퍼지 접속사, 퍼지 분리와 같은 퍼지 논리 접속사로 연결된 기본 퍼지 진술.
S는 조건 A의 참 정도의 알려진 값을 기반으로 결론 B의 참 정도의 양적 값을 결정하는 방법 또는 방법입니다. 이 방법은 프로덕션 퍼지 시스템에서 퍼지 추론 방식 또는 알고리즘을 정의하고 다음과 같습니다. ~라고 불리는 구성 방법또는 활성화 방법.
신뢰 요인 F는 퍼지 제품의 진실 정도 또는 상대적 가중치에 대한 정량적 평가를 나타냅니다. 신뢰 계수는 간격에서 값을 취하며 퍼지 생성 규칙의 가중치 계수라고도 합니다.
퍼지 프로덕션 사후 조건 N은 프로덕션 코어 구현의 경우 수행해야 하는 작업 및 절차를 설명합니다. B의 진실에 대한 정보 획득. 이러한 작업의 특성은 매우 다를 수 있으며 생산 시스템의 계산 또는 기타 측면을 반영합니다.
퍼지 생산 규칙 형식의 일관된 집합 퍼지 생산 시스템.따라서 퍼지 생산 시스템은 퍼지 생산 규칙 "IF A THEN B"의 도메인별 목록입니다.
가장 간단한 옵션퍼지 생산 규칙:
규칙<#>: IF β 1 "IS ά 1" THEN "β 2 IS ά 2"
규칙<#>: IF " β 1 IS ά 1 " THEN " β 2 display:block IS ά 2 ".
퍼지 프로덕션 코어의 선행 및 결과는 연결 "AND", "OR", "NOT"로 구성되어 복잡할 수 있습니다. 예를 들면 다음과 같습니다.
규칙<#>: "β 1 IS ά" 및 "β 2 IS NOT ά"이면 "β 1 IS NOT β 2"
규칙<#>: IF « β 1 IS ά » AND « β 2 IS NOT ά » THEN « β 1 IS NOT β 2 ».
가장 자주 퍼지 생성 규칙의 기본은 사용된 언어 변수와 관련하여 일관된 구조화된 텍스트의 형태로 제공됩니다.
RULE_1: IF "Condition_1" THEN "Conclusion_1"(F 1 t),
RULE_n: IF "Condition_n" THEN "Conclusion_n"(F n),
여기서 F i ∈는 확실성 인자 또는 해당 규칙의 가중 인자입니다. 목록의 일관성은 이진 연산 "AND", "OR"로 연결된 단순 및 복합 퍼지 문만 규칙의 조건 및 결론으로 사용할 수 있음을 의미하지만 각 퍼지 문에서는 용어 집합 값의 소속 함수 각 언어 변수에 대해 정의해야 합니다. 일반적으로 개별 항의 소속 함수는 삼각형 또는 사다리꼴 함수로 표시됩니다. 다음 약어는 일반적으로 개별 용어의 이름을 지정하는 데 사용됩니다.
표 2.3.

예시.액체의 연속적인 제어 흐름과 제어되지 않은 액체의 연속 흐름이 있는 벌크 탱크(탱크)가 있습니다. 탱크의 액체 레벨이 평균을 유지하기 위해 어떤 액체 유입을 선택해야 하는지에 대한 전문가의 지식에 해당하는 퍼지 추론 시스템의 규칙 기반은 다음과 같습니다.
| 규칙<1>: | 그리고 "액체 소모가 크다" | ~까지 "유체 유입 | 큰 중간 작은 | »; | |
| 규칙<2>: | IF "수위가 낮다" | 그리고 "유체 소비는 평균" | ~까지 "유체 유입 | 큰 중간 작은 | »; |
| 규칙<3>: | IF "수위가 낮다" | 그리고 "유체 소모가 적다" | ~까지 "유체 유입 | 큰 중간 작은 | »; |
| 규칙<4>: | 그리고 "액체 소모가 크다" | ~까지 "유체 유입 | 큰 중간 작은 | »; | |
| 규칙<5>: | IF "액위가 중간" | 그리고 "유체 소비는 평균" | ~까지 "유체 유입 | 큰 중간 작은 | »; |
| 규칙<6>: | IF "액위가 중간" | 그리고 "유체 소모가 적다" | ~까지 "유체 유입 | 큰 중간 작은 | »; |
| 규칙<7>: | 그리고 "액체 소모가 크다" | ~까지 "유체 유입 | 큰 중간 작은 | »; | |
| 규칙<8>: | IF "액위가 높다" | 그리고 "유체 소비는 평균" | ~까지 "유체 유입 | 큰 중간 작은 | »; |
| 규칙<9>: | IF "액위가 높다" | 그리고 "유체 소모가 적다" | ~까지 "유체 유입 | 큰 중간 작은 | ». |
ZP - "소형", PM - "중형", PB - "대형" 지정 사용, 이 베이스퍼지 생산 규칙은 필요한 유체 유입에 대한 해당 결론이 있는 노드에서 테이블 형태로 나타낼 수 있습니다.
표 2.4.
|
||||||||||||||||||||
예시.탱크의 액체 레벨과 액체 유량에 대한 설명의 형식화는 언어적 변수를 사용하여 수행되었으며, 그 튜플에는 small, medium 및 small의 개념에 해당하는 세 개의 퍼지 변수가 포함되어 있습니다. 매우 중요한해당 물리량, 소속 함수는 그림 2.19에 나와 있습니다.
삼각형 사다리꼴 Z-선형 S-선형
삼각형 사다리꼴 Z-선형 S-선형
현재 레벨:
삼각형 사다리꼴 Z-선형 S-선형
삼각형 사다리꼴 Z-선형 S-선형
삼각형 사다리꼴 Z-선형 S-선형
현재 소비:
그림 2.19. 작은, 중간, 큰 수준 및 유체 흐름의 퍼지 개념에 각각 해당하는 언어 변수 튜플의 구성원 함수
액체의 현재 수준과 유속이 각각 2.5m 및 0.4m 3 /sec이면 퍼지를 사용하여 기본 퍼지 진술의 진실 정도를 얻습니다.
- "액위가 작습니다" - 0.75;
- "액체 수준은 평균입니다" - 0.25;
- "액체 수준이 높음" - 0.00;
- "액체 유량이 작다" - 0.00;
- "유체 소비는 평균입니다"- 0.50;
- "큰 유체 흐름" - 1.00.
집합퍼지 추론 시스템의 각 규칙에 대한 조건의 참 정도를 결정하는 절차입니다. 이 경우, 퍼지 생성 규칙의 커널의 위 조건(전례)을 구성하는 퍼지 단계에서 구한 언어 변수의 항의 소속 함수 값을 사용한다.
퍼지 생성 규칙의 조건이 단순 퍼지 진술이면 그 진리의 정도는 언어 변수의 해당 항의 소속 함수 값에 해당합니다.
조건이 복합 진술을 나타내는 경우 복합 진술의 진실 정도는 미리 정의된 기반 중 하나에서 이전에 도입된 퍼지 논리 연산을 사용하여 구성 기본 진술의 알려진 진실 값을 기반으로 결정됩니다.
예를 들어, 퍼지화의 결과로 얻은 기본 명제의 진리값을 고려하여, 의 정의에 따라 탱크의 액체 레벨을 제어하기 위한 퍼지 추론 시스템의 각 복합 규칙에 대한 조건의 진리도 다음은 두 개의 기본 명제 A, B의 퍼지 논리 "AND": T(A ∩ B)=min(T(A);T(B)) 입니다.
규칙<1>: 선행 조건 - "액위가 작음" 및 "액체 흐름이 큼"; 진실의 정도
선행 최소값(0.75 ;1.00 )=0.00 .
규칙<2>: 선행 - "액체 수준이 작음" 및 "액체 흐름이 중간임"; 진실의 정도
선행 최소값(0.75 ;0.50 )=0.00 .
규칙<3>: 선행조건 - "액위가 작다" AND "액량이 작다", 진리의 정도
선행 최소값(0.75 ;0.00 )=0.00 .
규칙<4>: 선행 조건 - "유체 수위는 중간" 및 "액체 흐름은 큼" 진실의 정도
선행 최소값(0.25 ;1.00 )=0.00 .
규칙<5>: 전건 - "유체 수준은 평균" AND "유체 흐름은 평균" 진실의 정도
선행 최소값(0.25 ;0.50 )=0.00 .
규칙<6>: 선행 조건 - "유체 수위는 중간" 및 "액체 흐름은 작음" 진실의 정도
선행 최소값(0.25 ;0.00 )=0.00 .
규칙<7>: 전건 - "액위가 크다" AND "액체 흐름이 크다", 진리의 정도
선행 최소값(0.00 ;1.00 )=0.00 .
규칙<8>: 선행 조건 - "높은 액체 수준" 및 "중간 액체 흐름", 진실의 정도
선행 최소값(0.00 ;0.50 )=0.00 .
규칙<9>: 선례 - "액면이 크다" AND "액량이 작다", 진리의 정도
선행 최소값(0.00 ;0.00 )=0.00 .
|
||||||||||||||||||||
활성화퍼지 추론 시스템에서 모든 퍼지 생성 규칙의 커널 결과를 구성하는 각 기본 논리 진술(하위 결론)의 참 정도를 찾는 절차 또는 프로세스입니다. 출력 언어 변수에 대한 결론이 내려지기 때문에 기본 하위 결론의 참 정도는 활성화 동안 기본 멤버십 함수와 연결됩니다.
퍼지 생성 규칙의 결론(결과)이 단순한 퍼지 진술이면 그 진리의 정도는 가중치 계수의 대수 곱과 이 퍼지 생성 규칙의 선행 항목의 진리도와 같습니다.
결론이 복합 명제이면 각 기본 명제의 참 정도는 가중치 계수의 대수 곱과 주어진 퍼지 생성 규칙의 선행 조건의 참 정도와 같습니다.
생성 규칙의 가중치 계수가 규칙 기반 생성 단계에서 명시적으로 지정되지 않은 경우 기본값은 1과 같습니다.
모든 생성 규칙의 결과에 대한 각 기본 하위 결론의 소속 함수 μ(y)는 퍼지 구성 방법 중 하나를 사용하여 찾습니다.
- 최소 활성화 – μ(y) = min( c ; μ(x) ) ;
- prod-활성화 - μ(y) = c μ(x) ;
- 평균 활성화 – μ(y) =0.5(c + μ(x)) ;
여기서 μ(x)와 c는 각각 언어 변수 항의 소속 함수와 퍼지 생성 규칙의 커널의 해당 결과(결과)를 형성하는 퍼지 진술의 진실 정도입니다.
예시.탱크의 유체 유입에 대한 설명의 형식화를 언어 변수를 사용하여 수행하면 튜플에 유체 유입의 작은, 중간 및 큰 값의 개념에 해당하는 3개의 퍼지 변수가 포함되며, 소속 함수 그 중 그림 2.19에 나와 있으며, 액체 유입을 변경하여 탱크의 액체 수위를 제어하기 위한 퍼지 추론 시스템의 생성 규칙에 대해 최소 활성화가 있는 모든 하위 결론의 구성원 함수는 다음과 같습니다(그림 2.20 (a), (b)).
그림 2.20(a). 작은, 중간, 큰 액체가 탱크로 유입된다는 퍼지 개념에 해당하는 언어 변수 튜플의 구성원 함수 및 탱크의 액체 레벨 제어 시스템의 퍼지 생성 규칙의 모든 하위 결론의 최소 활성화
그림 2.20(b). 작은, 중간, 큰 액체가 탱크로 유입된다는 퍼지 개념에 해당하는 언어 변수 튜플의 구성원 함수 및 탱크의 액체 레벨 제어 시스템의 퍼지 생성 규칙의 모든 하위 결론의 최소 활성화
축적(또는 저장) 퍼지 추론 시스템에서 출력 언어 변수 각각에 대한 소속 함수를 찾는 프로세스입니다. 누적의 목적은 하위 결론의 모든 진리 수준을 결합하여 각 출력 변수에 대한 소속 함수를 얻는 것입니다. 각 출력 언어 변수에 대한 누적 결과는 해당 언어 변수에 대한 퍼지 규칙 기반의 모든 하위 결론의 퍼지 집합의 합집합으로 정의됩니다. 모든 하위 결론의 소속 함수의 합집합은 일반적으로 고전적으로 수행됩니다. 사용 된:
- 대수 합집합 ∀ x ∈ X μ A+B x = μ A x + μ B x - μ A x ⋅ μ B x ,
- 경계 합집합 ∀ x ∈ X μ A B x = min( μ A x ⋅ μ B x ;1) ,
- 과감한 합집합 ∀ x ∈ X μ A ∇ B (x) = ( μ B (x) , e c l 및 μ A (x) = 0, μ A (x) , e c l 및 μ B (x) = 0 , 1, in 다른 경우,
- 또한 λ-합 ∀ x ∈ X μ (A+B) x = λ μ A x +(1-λ) μ B x ,λ∈ .
예시.액체 유입량을 변경하여 탱크의 액체 수위를 제어하는 퍼지 추론 시스템의 생성 규칙에 대해, max-union으로 모든 하위 결론을 누적한 결과 얻은 언어 변수 "유체 유입량"의 구성원 함수, 다음과 같이 보일 것입니다(그림 2.21).
그림 2.21 언어 변수 "유체 유입"의 소속 함수
역퍼지화퍼지 추론 시스템에서 이것은 출력 언어 변수의 소속 함수에서 명확한(숫자) 값으로 전환하는 과정입니다. 역퍼지화의 목적은 모든 출력 언어 변수의 누적 결과를 사용하여 퍼지 추론 시스템(지능형 ACS의 액츄에이터) 외부 장치에서 사용되는 각 출력 변수에 대한 정량적 값을 얻는 것입니다.
누적 결과로 얻은 출력 언어 변수의 소속 함수 μ(x)에서 출력 변수의 수치 y로의 전환은 다음 방법 중 하나로 수행됩니다.
- 무게중심법(Centre of Gravity)는 계산하는 것입니다. 면적 중심 y = ∫ x 최소 x 최대 x μ (x) d x ∫ x 최소 x 최대 μ (x) d x , 여기서 [ x 최대 ; x min ]은 출력 언어 변수의 퍼지 집합의 반송파입니다. (그림 2.21에서 역퍼지화 결과는 녹색선으로 표시)
- 센터 에어리어 방식(Centre of Area) 소속 함수 곡선 μ(x), 소위 영역 이등분선 ∫ x min y μ(x) dx = ∫ yx max μ(x) dx로 경계를 이루는 영역을 나누는 가로 좌표계 y를 계산하는 것으로 구성됩니다. (그림 2.21에서 역퍼지화 결과는 파란색 선으로 표시)
- 왼쪽 모달 값 방법 y= x 최소 ;
- 오른쪽 모달 값 방법 y=xmax
예시.액체 유입을 변경하여 탱크의 액체 수위를 제어하기 위한 퍼지 추론 시스템의 생성 규칙에 대해 언어 변수 "liquid inflow"(그림 2.21)의 소속 함수의 비퍼지화는 다음 결과로 이어집니다.
- 무게 중심 방법 y= 0.35375 m 3 /초;
- 영역 중심의 방법 y \u003d 0, m 3 / s
- 왼쪽 모달 값 방법 y= 0.2 m 3 /sec;
- 오른쪽 모달 값 방법 y= 0.5m 3 /초
퍼지 추론의 고려 단계는 모호한 방식으로 구현될 수 있음: 집계는 Zadeh의 퍼지 논리를 기반으로 할 뿐만 아니라 다양한 퍼지 구성 방법으로 활성화가 수행될 수 있으며 누적 단계에서는 합집합이 수행될 수 있음 max-combination과는 다른 방식으로 역퍼지화(defuzzification)도 다양한 방법으로 수행할 수 있다. 따라서 퍼지 추론의 개별 단계를 구현하는 특정 방법을 선택하면 하나 또는 다른 퍼지 추론 알고리즘이 결정됩니다. 현재 특정 기술 문제에 따라 퍼지 추론 알고리즘을 선택하는 기준과 방법에 대한 질문은 열려 있습니다. 현재 퍼지 추론 시스템에서 가장 많이 사용되는 알고리즘은 다음과 같다.
알고리즘 Mamdani(맘다니)첫 번째 퍼지 시스템에서 응용 프로그램을 찾았습니다. 자동 제어. 증기 기관을 제어하기 위해 영국 수학자 E. Mamdani가 1975년에 제안했습니다.
- 퍼지 추론 시스템의 규칙 기반은 "IF A THEN B" 형식의 퍼지 생성 규칙의 순서화된 합의 목록의 형태로 형성되며, 여기서 퍼지 생성 규칙의 커널의 선행 조건은 논리적 접속사 "AND "이고 퍼지 생성 규칙의 커널 결과는 간단합니다.
- 입력 변수의 퍼지화는 퍼지 추론 시스템을 구성하는 일반적인 경우와 마찬가지로 위와 같은 방식으로 수행된다.
- 퍼지 생성 규칙의 하위 조건 집계는 두 개의 기본 문장 A, B의 고전적인 퍼지 논리 연산 "AND"를 사용하여 수행됩니다. T(A ∩ B) = min( T(A);T(B) ) .
- 퍼지 생성 규칙의 하위 결론의 활성화는 최소 활성화 방법 μ(y) = min(c; μ(x) )에 의해 수행됩니다. 여기서 μ(x) 및 c는 각각 언어 용어의 소속 함수입니다. 퍼지 생산 규칙의 상응하는 결과(결과적) 커널을 형성하는 퍼지 진술의 변수 및 진실의 정도.
- 퍼지 생성 규칙의 하위 결론의 누적은 퍼지 논리 최대 합집합 멤버쉽 함수 ∀ x ∈ X μ A B x = max( μ A x ; μ B x ) 에 대한 고전을 사용하여 수행됩니다.
- 역퍼지화는 무게중심법 또는 면적중심법을 사용하여 수행된다.
예를 들어, 위에서 설명한 탱크 수위 제어의 경우는 역퍼지화 단계에서 출력 변수의 명확한 값을 무게 중심 또는 면적 방법으로 구하는 경우 Mamdani 알고리즘에 해당합니다. y= 0.35375 m 3 /sec 또는 y= 0.38525 m 3 /초, 각각.
알고리즘 Tsukamoto(츠카모토)공식적으로는 이렇게 생겼습니다.
- 퍼지 생성 규칙의 하위 조건 집계는 Mamdani 알고리즘과 유사하게 두 개의 기본 문장 A, B의 고전적인 퍼지 논리 연산 "AND"를 사용하여 수행됩니다. T(A ∩ B) = min( T(A);T (나) )
- 퍼지 생성 규칙의 하위 결론 활성화는 두 단계로 수행됩니다. 첫 번째 단계에서 퍼지 생성 규칙의 결론(결과)의 참 정도는 Mamdani 알고리즘과 유사하게 이 퍼지 생성 규칙의 가중치 계수와 선행 항목의 참 정도의 대수적 곱으로 발견됩니다. 두 번째 단계에서는 Mamdani 알고리즘과 달리 각 생성 규칙에 대해 하위 결론의 소속 함수를 구성하는 대신 방정식 μ(x) = c를 풀고 출력 언어 변수의 명확한 값 ω를 결정합니다. , 여기서 μ(x) 및 c는 각각 언어 용어 변수의 소속 함수 및 퍼지 생성 규칙의 커널의 해당 결과(결과)를 형성하는 퍼지 진술의 진실 정도입니다.
- 역퍼지화 단계에서 각 언어 변수에 대해 개별 세트의 선명한 값에서 전환( w 1 .
여기서 n은 이 언어적 변수가 나타나는 하위 결론에서 퍼지 생성 규칙의 수이고, ci는 생성 규칙의 하위 결론의 진실 정도이고, wi는 다음과 같이 활성화 단계에서 얻은 이 언어적 변수의 명확한 값입니다. 방정식 μ (x) = ci , 즉 μ (wi) = c i 이고 μ (x)는 언어 변수의 해당 항의 소속 함수를 나타냅니다.
예를 들어, Tsukamoto 알고리즘은 위에서 설명한 탱크 레벨 제어의 경우에 구현됩니다.
- 활성화 단계에서 그림 2.20의 데이터를 사용하고 각 생산 규칙에 대해 방정식 μ(x) = c i를 그래픽으로 풉니다. 값 쌍 찾기(ci , wi): 규칙 1 - (0.75 ; 0.385), 규칙 2 - (0.5 ; 0.375), 규칙 3- (0 ; 0), 규칙 4 - (0.25 ; 0.365), 규칙 5 - ( 0.25 ; 0.365 ),
규칙 6 - (0 ; 0), 규칙 7 - (0 ; 0), 규칙 7 - (0 ; 0), 규칙 8 - (0 ; 0), 규칙 9 - (0 ; 0), 다섯 번째 규칙에는 두 개의 근이 있습니다. - 언어 변수 "유체 유입"에 대한 역퍼지화 단계에서 명확한 값의 이산 세트( ω 1 . . . ω n )에서 중심의 이산 아날로그에 따라 단일 명확한 값으로의 전환을 수행합니다. 중력 방법 y = ∑ i = 1 nciwi ∑ i = 1 nci , y = 0.35375 m 3 / s
Larsen의 알고리즘은 공식적으로 다음과 같습니다.
- 퍼지 추론 시스템의 규칙 기반 형성은 Mamdani 알고리즘과 유사하게 수행됩니다.
- 입력 변수의 퍼지화는 Mamdani 알고리즘과 유사하게 수행됩니다.
- 퍼지 생성 규칙의 하위 결론의 활성화는 prod-activation 방법, μ(y)=c μ(x)에 의해 수행됩니다. 여기서 μ(x) 및 c는 각각 언어 변수 항의 소속 함수 및 정도입니다. 퍼지 커널 생산 규칙의 상응하는 결과(결과)를 형성하는 퍼지 진술의 진실.
- 퍼지 생성 규칙의 하위 결론의 누적은 멤버십 함수 T(A ∩ B) = min( T(A);T(B) ) 의 고전적인 퍼지 논리 최대 합집합을 사용하는 Mamdani 알고리즘과 유사하게 수행됩니다.
- 역퍼지화는 위에서 논의한 방법 중 하나로 수행됩니다.
예를 들어, Larsen 알고리즘은 위에서 설명한 탱크 수준 제어의 경우 활성화 단계에서 prod-활성화에 따른 모든 하위 결론의 소속 함수를 얻은 경우 구현됩니다(그림 2.22(a),(b)), 소속 최대 통일로 모든 하위 결론을 누적한 결과 얻은 언어 변수 "유체 유입"의 함수는 다음과 같을 것이며(그림 2.22(b)), 언어 변수 "유체 유입"의 소속 함수의 역퍼지화는 다음과 같습니다. "는 다음과 같은 결과로 이어집니다. 무게 중심 방법 y= 0.40881 m 3 /sec, 면적 중심 방법 y \u003d 0.41017 m 3 / s
그림 2.22(a) 탱크의 액체 레벨 제어 시스템의 퍼지 생산 규칙의 모든 하위 결론의 활성화
그림 2.22(b) 탱크의 액체 레벨 제어 시스템의 퍼지 생성 규칙의 모든 하위 결론과 max-union으로 얻은 언어 변수 "liquid inflow"의 멤버쉽 함수의 Prod-활성화
,스게노 알고리즘다음과 같이.
- 퍼지 추론 시스템의 규칙 기반은 "IF A AND B THEN w = ε 1 a + ε 2 b" 형식의 퍼지 생성 규칙의 순서화된 합의 목록의 형태로 형성되며, 여기서 코어의 선행 조건은 퍼지 생성 규칙은 논리적 연결 "AND"를 사용하는 두 개의 간단한 퍼지 문 A, B로 구성되며, a 및 b는 각각 문 A 및 B에 해당하는 입력 변수의 명확한 값이며, ε 1 및 ε 2는 가중치 계수입니다. 입력 변수의 명확한 값과 퍼지 추론 시스템의 출력 변수 사이의 비례 계수를 결정하고, w는 퍼지 규칙의 결론에서 정의된 출력 변수의 명확한 값을 실수로 정의합니다.
- 명령문을 정의하는 입력 변수의 퍼지화 및 Mamdani의 알고리즘과 유사하게 수행됩니다.
- 퍼지 생성 규칙의 하위 조건 집계는 Mamdani 알고리즘과 유사하게 두 개의 기본 명령문 A, B의 고전적인 퍼지 논리 연산 "AND"를 사용하여 수행됩니다. T(A ∩ B) = min( T(A);T(B) ) .
- “퍼지 생산 규칙의 하위 결론 활성화는 두 단계로 수행됩니다. 첫 번째 단계에서 출력 변수를 실수와 연관시키는 퍼지 생성 규칙의 결론(결과)의 진리도 c는 Mamdani 알고리즘과 유사하게 가중치 계수와 진리도의 대수적 곱으로 발견됩니다. 이 퍼지 생산 규칙의 전례. 두 번째 단계에서는 Mamdani 알고리즘과 달리 각 생성 규칙에 대해 하위 결론의 소속 함수를 명시적 형식으로 구성하는 대신 출력 변수 w = ε 1 a + ε 2 b의 명확한 값을 찾습니다. . 따라서 각 i번째 생산 규칙에는 점(ci w i)이 할당됩니다. 여기서 c i는 생산 규칙의 진실 정도이고, w i는 생산 규칙의 결과에 정의된 출력 변수의 명확한 값입니다.
- 퍼지 생성 규칙의 결론 누적은 활성화 단계에서 각 출력 언어 변수에 대해 선명한 값의 개별 집합이 이미 얻어졌기 때문에 수행되지 않습니다.
- 역퍼지화는 Tsukamoto 알고리즘에서와 같이 수행됩니다. 각 언어 변수에 대해 무게 중심 방법 y = ∑ i = 1 nciwi ∑의 이산 아날로그에 따라 선명한 값의 이산 집합( w 1 ... wn )에서 단일 선명한 값으로 전환됩니다. i = 1 nci , 여기서 n은 이 언어적 변수가 나타나는 하위 결론에서 퍼지 생성 규칙의 수이고, ci는 생성 규칙의 하위 결론의 진실 정도이고, wi는 이 언어적 변수의 명확한 값입니다. 생산 규칙의 결과로.
예를 들어,전술한 탱크 내 수위 조절의 경우 퍼지 추론 시스템의 룰 베이스를 형성하는 단계에서 일정한 수위를 유지하면서, 유입량 w와 유량 b의 수치는 서로 같아야 하며 ε 2 =1이고 탱크의 충전율은 유입량 w와 액체 사이의 비례 계수 ε 1의 상응하는 변화에 의해 결정됩니다. 레벨 라. 이 경우, 탱크의 액체 레벨이 평균을 유지하기 위해 어떤 유체 유입 w = ε 1 a + ε 2 b를 선택해야 하는지에 대한 전문가의 지식에 해당하는 퍼지 추론 시스템의 규칙 기반은 다음과 같습니다. 이것:
규칙<1>: IF "액면이 작음" 및 "액체 흐름이 큼" THEN w=0.3a+b;
규칙<2>: IF "액위가 낮음" 및 "액체 흐름이 중간임" THEN w=0.2a+b;
규칙<3>: IF "액위가 낮음" AND "액량이 적음" THEN w=0.1a+b ;
규칙<4>: IF "액위가 중간임" 및 "액체 흐름이 큼" THEN w=0.3a+b;
규칙<5>: IF "액위는 평균"이고 "액체 흐름은 평균" THEN w=0.2a+b;
규칙<6>: IF "액위가 중간"이고 "액량이 적음" THEN w=0.1a+b;
규칙<7>: IF "액위가 크다" AND "액체 흐름이 크다" THEN w=0.4a+b;
규칙<8>: IF "액면이 크다" AND "액체 흐름이 평균이다" THEN w=0.2a+b;
규칙<9>: IF "액위가 크다" AND "액량이 작다" THEN w=0.1a+b.
이전에 고려한 전류 레벨 및 유량에서 a= 2.5 m 및 b= 0.4 m 3 /sec에서 출력 변수의 명확한 값의 명시적 정의를 고려하여 퍼지화, 집계 및 활성화의 결과 생산 규칙의 결과, 우리는 값 쌍(ciwi)을 얻습니다: 규칙1 - (0.75 ; 1.15), 규칙2 - (0.5 ; 0.9), 규칙3- (0 ; 0.65), 규칙4 - (0.25 - (0.25 ; 0.9), 규칙 6 - (0 ; 0.65), 규칙 7 - (0 ; 0), 규칙 7 - (0 ; 1.14), 규칙 8 - (0 ; 0.9), 규칙 9 - (0 ; 0, 65). 언어 변수 "유체 유입"에 대한 역퍼지화 단계에서, 무게 중심의 이산 아날로그에 따라 선명한 값의 이산 세트( w 1 . . . wn )에서 단일 크리스프 값으로의 전환이 이루어집니다. 방법 y = ∑ i = 1 nciwi ∑ i = 1 nci , y= 1.0475 m 3 /sec
단순화된 퍼지 추론 알고리즘공식적으로는 Sugeno 알고리즘과 정확히 같은 방식으로 지정되지만, w= ε 1 a+ ε 1 b 관계 대신에 생산 규칙의 결과에 명확한 값을 명시적으로 지정할 때만 w의 직접 값이 명시적으로 지정됩니다. 따라서 퍼지 추론 시스템의 규칙 기반의 형성은 "IF A AND B THEN w=ε" 형식의 퍼지 생성 규칙의 순서화된 일관된 목록의 형태로 수행되며, 여기서 퍼지 커널의 선행 조건은 생산 규칙은 논리 연결 "AND"를 사용하는 두 개의 간단한 퍼지 문 A, B에서 작성됩니다. w - i 번째 규칙의 각 결론에 대해 정의된 출력 변수의 명확한 값, 실수 ε i .
예를 들어,위에서 설명한 탱크의 수위 제어의 경우 퍼지 추론 시스템의 규칙 기반을 형성하는 단계에서 규칙이 다음과 같이 지정되면 단순화된 퍼지 추론 알고리즘이 구현됩니다.
규칙<1>: IF "액면이 작음" 및 "액체 흐름이 큼" THEN w=0.6;
규칙<2>: IF "액위가 낮음" 및 "액체 흐름이 평균임" THEN w=0.5;
규칙<3>: IF "액위가 낮음" 및 "액량이 적음" THEN w=0.4;
규칙<4>: IF "액위가 중간임" 및 "액체 흐름이 큼" THEN w=0.5;
규칙<5>: IF "액위가 평균임" 및 "액체 흐름이 평균임" THEN w=0.4;
규칙<6>: IF "액위가 중간임" 및 "액체 흐름이 작음" THEN w=0.3;
규칙<7>: IF "액위가 크다" 및 "액체 흐름이 크다" THEN w=0.3;
규칙<8>: IF "액위가 크다" 및 "액체 흐름이 평균" THEN w=0.2;
규칙<9>: IF "액위가 크다" AND "액량이 작다" THEN w=0.1.
현재 수준과 유속이 이미 고려되어 있으므로 퍼지화, 집계 및 활성화의 결과로 생산 규칙의 결과에서 출력 변수의 명확한 값의 명시적 정의를 고려하여 다음 쌍을 얻습니다. 값(ciwi) : 규칙1 - (0.75; 0.6), 규칙2 - (0.5; 0.5), 규칙3 - (0; 0.4), 규칙4 - (0.25; 0.5), 규칙5 - (0.25; 0.4), 규칙6 - ( 0 ; 0.3),
규칙 7 - (0 ; 0.3), 규칙 7 - (0 ; 0.3), 규칙 8 - (0 ; 0.2), 규칙 9 - (0 ; 0.1) . 언어 변수 "유체 유입"에 대한 역퍼지화 단계에서, 무게 중심의 이산 아날로그에 따라 선명한 값의 이산 세트( w 1 . . . wn )에서 단일 크리스프 값으로의 전환이 이루어집니다. 방법 y = ∑ 나는 = 1 nciwi ∑ 나는 = 1 nci , y= 1.0475 m 3 / s, y \u003d 0.5 m 3 / s
퍼지 집합을 사용하여 "고온" 또는 "대도시"와 같은 부정확하고 모호한 개념을 공식적으로 정의할 수 있습니다. 퍼지 집합의 정의를 공식화하려면 소위 추론 영역을 설정할 필요가 있습니다. 예를 들어 자동차의 속도를 추정할 때 X = 범위로 제한합니다. 여기서 Vmax는 자동차가 도달할 수 있는 최대 속도입니다. X는 선명한 집합이라는 것을 기억해야 합니다.
기본 컨셉
퍼지 세트비어 있지 않은 공간에서 A는 쌍의 집합입니다.어디에 ![]()
- 퍼지 집합 A의 소속 함수. 이 함수는 각 요소 x에 퍼지 집합 A의 소속 정도를 할당합니다.
이전 예를 계속해서 세 가지 부정확한 공식을 고려하십시오.
- "낮은 차량 속도";
- "평균 차량 속도";
- "자동차의 고속."
그림은 소속 함수를 사용하여 위의 공식에 해당하는 퍼지 집합을 보여줍니다. 
고정된 지점에서 X=40km/h. 퍼지 집합 "낮은 차량 속도"의 소속 함수는 0.5 값을 취합니다. 퍼지 집합 "average car speed"의 소속 함수는 동일한 값을 취하는 반면, 집합 "high car speed"의 경우 이 지점에서 함수의 값은 0입니다.
두 변수 T: x ->의 함수 T가 호출됩니다. T-norm, 만약:
- 두 인수에 대해 증가하지 않음: T(a, c)< T(b, d) для a < b, c < d;
- 가환성: T(a, b) = T(b, a);
- 연결 조건 충족: T(T(a, b), c) = T(a, T(b, c));
- 경계 조건 충족: T(a, 0) = 0, T(a, 1) = a.
직접 퍼지 추론
아래에 퍼지 추론일부 결과(아마도 퍼지일 수도 있음)가 퍼지 전제에서 얻어지는 과정으로 이해됩니다. 대략적인 추론은 자연어를 이해하고, 손글씨를 읽고, 정신적 노력이 필요한 게임을 하고, 일반적으로 복잡하고 불완전하게 정의된 환경에서 결정을 내리는 능력의 기초가 됩니다. 정성적이고 부정확한 용어로 추론하는 이러한 능력은 인간의 지능을 컴퓨터의 지능과 구별합니다.전통적인 논리의 주요 추론 규칙은 modus ponens 규칙에 따라 진술 A와 A -> B의 진실로 진술 B의 진실을 판단합니다. 예를 들어 A가 진술 "Stepan은 우주 비행사"인 경우, B는 "Stepan이 우주로 날아간다"는 진술이고, "Stepan은 우주 비행사이다"와 "Stepan이 우주 비행사이면 그는 우주로 날아간다"가 참이면 "Stepan이 우주로 날아간다"도 참이다. .
그러나 전통적인 논리와 달리 퍼지 논리의 주요 도구는 modus ponens 규칙이 아니라 modus ponens 규칙이 매우 특별한 경우인 소위 구성 추론 규칙입니다.
곡선 y=f(x)가 있고 값 x=a가 주어졌다고 가정합니다. 그런 다음 y=f(x) 및 x=a라는 사실로부터 y=b=f(a)라는 결론을 내릴 수 있습니다. 
이제 a는 간격이고 f(x)는 값이 간격인 함수라고 가정하여 이 과정을 일반화합니다. 이 경우 간격 a에 해당하는 간격 y=b를 찾기 위해 먼저 밑이 a인 집합 a"를 구성하고 값이 간격인 곡선과 교집합 I을 찾습니다. 그런 다음 이 교집합을 OY에 투영합니다. 축 및 구간 b에서 원하는 y 값을 얻습니다. 따라서 y=f(x) 및 x=A가 OX 축의 퍼지 부분 집합이라는 사실에서 y 값을 퍼지 부분 집합 B로 얻습니다. OY 축.
U와 V를 각각 기본 변수 u와 v를 갖는 두 개의 보편적인 집합이라고 하자. A와 F를 집합 U와 U x V의 퍼지 부분 집합이라고 하자. 그러면 구성 추론 규칙에 따르면 퍼지 집합 B = A * F는 퍼지 집합 A와 F에서 나옵니다.
A와 B를 퍼지 문이라고 하고 m(A), m(B)를 이에 대응하는 소속 함수라고 하자. 그러면 암시 A -> B는 일부 소속 함수 m(A -> B)에 해당합니다. 전통적인 논리와 유추하여 다음과 같이 가정할 수 있습니다.
그 다음에
그러나 이것이 함축 연산자의 유일한 일반화는 아니며 다른 것도 있습니다.
구현
직접 퍼지 추론 방법을 구현하려면 함축 연산자와 T-norm을 선택해야 합니다.T-norm을 최소 함수로 둡니다.
함축 연산자는 괴델 함수가 됩니다.
입력 데이터에는 지식(퍼지 세트) 및 규칙(함유)이 포함됩니다. 예를 들면 다음과 같습니다.
A = ((x1, 0.0), (x2, 0.2), (x3, 0.7), (x4, 1.0)).
B = ((x1, 0.7), (x2, 0.4), (x3, 1.0), (x4, 0.1)).
A => B.
함축은 데카르트 행렬로 표시되며 각 요소는 선택한 함축 연산자(이 예에서는 Gödel 함수)를 사용하여 계산됩니다.
- def compute_impl(set1, set2):
- """
컴퓨팅 의미
"""- 관계 = ()
- set1.items()에서 i의 경우:
- 관계[i] = ()
- set2.items()의 j에 대해:
- v1 = set1.value(i)
- v2 = set2.value(j)
- 관계[i][j] = impl(v1, v2)
- 반환 관계
위 데이터의 경우 다음과 같습니다.
결론:
A => B.
x1 x2 x3 x4
x1 1.0 1.0 1.0 1.0
x2 1.0 1.0 1.0 0.1
x3 1.0 0.4 1.0 0.1
x4 0.7 0.4 1.0 0.1
- def 결론 (집합, 관계):
- """
결론
"""- conl_set =
- 나는 관련하여 :
- 내가 =
- 관계[i]에서 j에 대해:
- v_set = 세트.값(i)
- v_impl = 관계[i][j]
- l.append(t_norm(v_set, v_impl))
- 값 = 최대(엘)
- conl_set.append((i, 값))
- 반환 conl_set
결과:
B" = ((x1, 1.0), (x2, 0.7), (x3, 1.0), (x4, 0.7)).
출처
- Rutkovskaya D., Pilinsky M., Rutkovsky L. 신경망, 유전 알고리즘 및 퍼지 시스템: Per. 폴란드어에서. I.D. 루딘스키. - M.: 핫라인 - Telecom, 2006. - 452 p.: 아프다.
- Zadeh L. A. 퍼지 세트, 정보 및 제어, 1965, vol. 8, s. 338-353
퍼지 세트. 언어적 변수. 퍼지 논리. 애매한 결론. 추론의 구성 규칙.
(추상적 인)
퍼지 집합(NS)의 개념은 공통 속성을 가진 특정 집합의 요소가 이 속성의 다른 정도의 퇴화를 가질 수 있고 결과적으로 이 속성에 다른 정도의 속함을 가질 수 있다는 아이디어를 기반으로 합니다.
U를 설정하자. U의 퍼지 집합 Ã는 ((µ Ã (u), u)) 형식의 쌍 모음이며, 여기서 u U, µ Ã 입니다.
값 μ Г는 퍼지 집합 U에 있는 객체의 소속 정도라고 합니다.
μ Ã : U
μ Ã는 소속 함수라고 합니다.
퍼지 집합의 예는 사람들의 나이입니다(그림 19.1).

전통적인 집합 이론과 유추하여 NM 이론은 다음 작업을 정의합니다.
노동 조합:
![]() , 어디
, 어디 ![]()
열거:
![]() ,
,
덧셈:
대수적 곱:
![]() , 어디
, 어디
집합에 정의된 n-항 퍼지 관계는 데카르트 곱의 퍼지 부분 집합입니다. ![]()
퍼지 관계는 집합이므로 퍼지 집합에 대해 정의된 모든 연산이 유효합니다. 퍼지 집합 이론의 실제 적용에서 퍼지 관계의 구성은 중요한 역할을 합니다.
퍼지 관계의 구성
2자리 퍼지 관계가 주어졌다고 하자.
퍼지 관계의 구성은 다음 식에 의해 결정됩니다.
 특정 표현의 소속 정도
특정 표현의 소속 정도



언어변수 - 5개의 X - 변수명(나이), U - 기본집합(0 ... 150), T(x) - 집합의 항이다. 언어적 의미 집합(청소년, 중년, 노인, 노인). 각각의 언어적 값은 U에 정의된 퍼지 집합의 레이블입니다. G는 변수 X(very young, very old)의 언어적 값을 생성하는 구문 규칙입니다. M은 기본 집합의 퍼지 부분 집합, 즉 소속 함수를 각 언어 값에 할당하는 의미 규칙입니다.
퍼지 진술은 주어진 시간에 그 참 또는 거짓의 정도를 판단할 수 있는 진술입니다. 진실은 간격에서 값을 취합니다. 더 간단한 것으로 나눌 수없는 퍼지 진술을 기본이라고합니다.
논리적 연결을 사용하여 기초적인 것 위에 구축된 퍼지 문을 복합 퍼지 문이라고 합니다. 논리적 연결은 퍼지 진술의 진실에 대한 연산에 해당합니다. - 특정 진술의 진실 정도.
2)
![]()
따라서 퍼지 집합의 대수는 퍼지 명제의 대수와 동형입니다.
4) 함축 연산
퍼지 논리에서 함축 연산에 대해 몇 가지 정의가 제안되었습니다. 기본:
1)
![]()
2)
![]()
3)
![]()
5) 동등성
집합 U 1 , U 2 ,… 2 ,… ,유 .
U 1 , U 2 ,… 그런 다음 퍼지 술어의 예는 다음과 같습니다.
"실린더의 압력이 낮습니다" - 한 자리 술어
"보일러의 온도가 열교환기의 온도보다 훨씬 높습니다" - 2자리 술어.

U k \u003d 1.5이면 "보일러의 압력이 낮습니다"\u003d 0.7
퍼지 알고리즘의 구성 및 구현에서 구성 추론 규칙은 중요한 역할을 합니다.
퍼지 매핑이 되자
우주 U의 퍼지 부분 집합은 V에서 퍼지 부분 집합을 생성합니다.

![]()
구성 추론 규칙은 퍼지 논리에서 논리적 추론을 구성하는 기초입니다.
퍼지 명제 가 주어졌다고 하자. where 및 are 퍼지 집합. 또한 어떤 진술(A에 가깝지만 동일하지는 않음)이 주어집니다.
고전 논리학에서는 Modus Ponens 추론 규칙이 널리 사용됩니다.
이 규칙은 퍼지 논리의 경우 다음과 같이 일반화됩니다.
집합을 기본 집합 X와 기본 집합 Y에 대해 정의합니다. if 문이 집합 X에서 Y로의 퍼지 매핑을 정의한다고 가정하는 것은 당연합니다.
![]()
그런 다음 구성 추론 규칙에 따라 다음을 얻습니다.
관계는 퍼지 논리에서 함축 연산의 정의를 기반으로 구축됩니다.
1)

보일러의 온도가 낮 으면 () 가열이 증가합니다 ()


실제 퍼지 논리 알고리즘에는 하나가 아닌 많은 생산 규칙이 포함됩니다.
S 1 이면 R 1 , 그렇지 않으면
S n 이면 R n , 그렇지 않으면
따라서 개별 규칙에 대해 퍼지 관계를 구축한 다음 서로 중첩하여 집계해야 합니다.



의미 유형에 따라 최소 또는 최대가 집계 작업으로 선택됩니다. 구성 산출 (규칙회선). 고려 된 논리 시스템에서 전제 조건이 결정됩니다. 언어적 변수 A1, A2, A3, 그리고 결론 - 언어적 변하기 쉬운 ...
방법론 흐린자율적인 광풍 에너지 시스템의 제어
초록 >> 정보학하나 흐린또는 언어적 변하기 쉬운, 흐린기능 또는 흐린관계. 그 다음에 흐린 ... 흐린함축. 실제로 흐린 산출그림에서. 2는 다음과 같이 maxmin 구성의 사용입니다. 구성 규정 흐린 산출 ...
...에이전트 기반 접근 방식 및 대화형 기반 논리학자
학위논문 >> 정보학, 프로그래밍... 산출다의미의 대화 작업에 흐린 논리학자 ... 언어적 ... 논리작은 차원, 그러나 힘이 증가함에 따라 세트진리 값 구성 및 사용 규칙 산출... 가치 변수교육받은...
"알로 트레이드" 시스템
논문 >> 금융과학아이콘은 규칙 구성 산출 (규칙회선) /3/. 고려 된 논리 시스템에서 전제 조건이 결정됩니다. 언어적 변수, 그리고 결론은 언어적 변하기 쉬운 B. 각 ...
경영 의사결정 요령서
치트 시트 >> 관리에서 세트주관적인 요인 - 논리... 값입니다 언어적 변하기 쉬운 X. 다음과 같이 가정합니다. 많은솔루션은 다음을 기반으로 결정됩니다. 구성 규정 산출: G \u003d Aº D, 여기서 G - 흐린구간 I의 부분집합....

