Direct fuzzy logical inference. Guidelines for laboratory work on the topic: “Fuzzy inference Learning a fuzzy inference system
The mathematical theory of fuzzy sets and fuzzy logic are generalizations of classical set theory and classical formal logic. These concepts were first proposed by the American scientist Lotfi Zadeh in 1965. The main reason for the emergence of a new theory was the presence of fuzzy and approximate reasoning when describing processes, systems, objects by a person.
Before the fuzzy approach to modeling complex systems was recognized all over the world, more than one decade had passed since the birth of the theory of fuzzy sets. And on this path of development of fuzzy systems, it is customary to distinguish three periods.
The first period (late 60s-early 70s) is characterized by the development of the theoretical apparatus of fuzzy sets (L. Zadeh, E. Mamdani, Bellman). In the second period (70–80s), the first practical results in the field of fuzzy control of complex technical systems (fuzzy control steam generator) appear. At the same time, attention began to be paid to the issues of building expert systems based on fuzzy logic, the development of fuzzy controllers. Fuzzy expert systems for decision support are widely used in medicine and economics. Finally, in the third period, which lasts from the late 80s and continues at the present time, software packages for building fuzzy expert systems appear, and the areas of application of fuzzy logic are noticeably expanding. It is used in the automotive, aerospace and transportation industries, in the field of household appliances, in the field of finance, analysis and management decision-making, and many others.
The triumphal march of fuzzy logic around the world began after the proof in the late 80s by Bartholomew Kosko famous theorem FAT (Fuzzy Approximation Theorem). In business and finance, fuzzy logic gained recognition when, in 1988, a fuzzy rule-based expert system for predicting financial indicators was the only one to predict a stock market crash. And the number of successful fuzzy applications is now in the thousands.
Mathematical apparatus
A characteristic of a fuzzy set is the Membership Function. Denote by MF c (x) the degree of membership in the fuzzy set C, which is a generalization of the concept of the characteristic function of an ordinary set. Then the fuzzy set C is the set of ordered pairs of the form C=(MF c (x)/x), MF c (x) . The value MF c (x)=0 means no membership in the set, 1 – full membership.
Let's illustrate this in simple example. We formalize the inaccurate definition of "hot tea". As x (reasoning area) will be the temperature scale in degrees Celsius. Obviously it will change from 0 to 100 degrees. The fuzzy set for the concept of "hot tea" may look like this:
C=(0/0; 0/10; 0/20; 0.15/30; 0.30/40; 0.60/50; 0.80/60; 0.90/70; 1/80; 1 /90; 1/100).
So, tea with a temperature of 60 C belongs to the "Hot" set with a membership degree of 0.80. For one person, tea at a temperature of 60 C may be hot, for another - not too hot. It is in this that the fuzziness of the assignment of the corresponding set manifests itself.
For fuzzy sets, as well as for ordinary ones, the main logical operations are defined. The most basic ones needed for calculations are intersection and union.
Intersection of two fuzzy sets (fuzzy "AND"): A B: MF AB (x)=min(MF A (x), MF B (x)).
Union of two fuzzy sets (fuzzy "OR"): A B: MF AB (x)=max(MF A (x), MF B (x)).
In the theory of fuzzy sets, a general approach to the execution of intersection, union, and addition operators has been developed, implemented in the so-called triangular norms and conorms. The above implementations of the intersection and union operations are the most common cases of the t-norm and t-conorm.
To describe fuzzy sets, the concepts of fuzzy and linguistic variables are introduced.
A fuzzy variable is described by a set (N,X,A), where N is the name of the variable, X is a universal set (reasoning area), A is a fuzzy set on X.
The values of a linguistic variable can be fuzzy variables, i.e. the linguistic variable is at a higher level than the fuzzy variable. Each linguistic variable consists of:
- titles;
- the set of its values, which is also called the base term-set T. The elements of the base term-set are the names of fuzzy variables;
- universal set X;
- a syntactic rule G, according to which new terms are generated using words of a natural or formal language;
- semantic rule P, which associates each value of a linguistic variable with a fuzzy subset of the set X.
Consider such a fuzzy concept as "share price". This is the name of the linguistic variable. Let's form a basic term-set for it, which will consist of three fuzzy variables: "Low", "Moderate", "High" and set the reasoning area in the form of X= (units). The last thing left to do is to build membership functions for each linguistic term from the base term-set T.
There are over a dozen typical curve shapes for defining membership functions. The most widespread are: triangular, trapezoidal and Gaussian membership functions.
The triangular membership function is defined by a triple of numbers (a,b,c), and its value at the point x is calculated according to the expression:
$$MF\,(x) = \,\begin(cases) \;1\,-\,\frac(b\,-\,x)(b\,-\,a),\,a\leq \,x\leq \,b &\ \\ 1\,-\,\frac(x\,-\,b)(c\,-\,b),\,b\leq \,x\leq \ ,c &\ \\ 0, \;x\,\not \in\,(a;\,c)\ \end(cases)$$
With (b-a)=(c-b) we have the case of a symmetric triangular membership function, which can be uniquely specified by two parameters from the triple (a,b,c).
Similarly, to set the trapezoidal membership function, four numbers (a, b, c, d) are needed:
$$MF\,(x)\,=\, \begin(cases) \;1\,-\,\frac(b\,-\,x)(b\,-\,a),\,a \leq \,x\leq \,b & \\ 1,\,b\leq \,x\leq \,c & \\ 1\,-\,\frac(x\,-\,c)(d \,-\,c),\,c\leq \,x\leq \,d &\\ 0, x\,\not \in\,(a;\,d) \ \end(cases)$$
With (b-a)=(d-c), the trapezoidal membership function takes on a symmetrical form.
The membership function of Gaussian type is described by the formula
$$MF\,(x) = \exp\biggl[ -\,(\Bigl(\frac(x\,-\,c)(\sigma)\Bigr))^2\biggr]$$
and operates on two parameters. Parameter c denotes the center of the fuzzy set, and the parameter is responsible for the steepness of the function.

The set of membership functions for each term from the base term-set T is usually shown together on one graph. Figure 3 shows an example of the linguistic variable "Stock price" described above, Figure 4 shows the formalization of the inaccurate concept of "Age of a person". So, for a person 48 years old, the degree of belonging to the set "Young" is 0, "Average" - 0.47, "Above average" - 0.20.
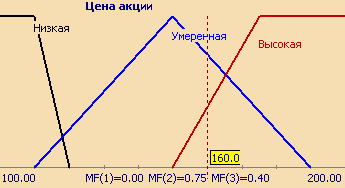

The number of terms in a linguistic variable rarely exceeds 7.
Fuzzy inference
The basis for carrying out the fuzzy inference operation is the rule base containing fuzzy statements in the form "If-then" and membership functions for the corresponding linguistic terms. In this case, the following conditions must be met:
- There is at least one rule for each linguistic term of the output variable.
- For any term of the input variable, there is at least one rule in which this term is used as a precondition (the left side of the rule).
Otherwise, there is an incomplete base of fuzzy rules.
Let the rule base have m rules of the form:
R 1: IF x 1 is A 11 … AND … x n is A 1n THEN y is B 1
…
R i: IF x 1 is A i1 … AND … x n is A in THEN y is B i
…
R m: IF x 1 is A i1 … AND … x n is A mn THEN y is B m ,
where x k , k=1..n – input variables; y is the output variable; A ik are given fuzzy sets with membership functions.
The result of fuzzy inference is a crisp value of the variable y * based on the given crisp values x k , k=1..n.
In general, the inference mechanism includes four stages: the introduction of fuzziness (fuzzification), fuzzy inference, composition and reduction to clarity, or defuzzification (see Figure 5).

Fuzzy inference algorithms differ mainly in the type of rules used, logical operations, and the type of defuzzification method. Mamdani, Sugeno, Larsen, Tsukamoto fuzzy inference models have been developed.
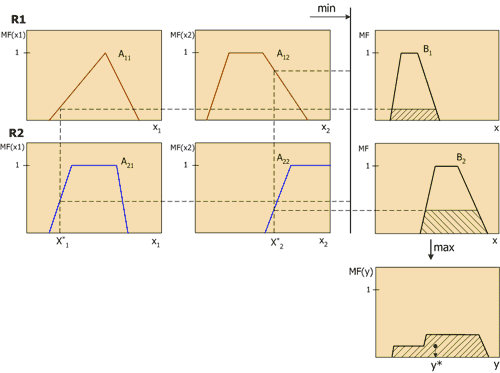
Let us consider fuzzy inference in more detail using the Mamdani mechanism as an example. This is the most common method of logical inference in fuzzy systems. It uses minimax composition of fuzzy sets. This mechanism includes the following sequence of actions.
- Fuzzification procedure: degrees of truth are determined, i.e. values of membership functions for the left parts of each rule (prerequisites). For a rule base with m rules, we denote the degrees of truth as A ik (x k), i=1..m, k=1..n.
Fuzzy conclusion. First, the "cutoff" levels for the left side of each of the rules are determined:
$$alfa_i\,=\,\min_i \,(A_(ik)\,(x_k))$$
$$B_i^*(y)= \min_i \,(alfa_i,\,B_i\,(y))$$
Composition, or union of the obtained truncated functions, for which the maximum composition of fuzzy sets is used:
$$MF\,(y)= \max_i \,(B_i^*\,(y))$$
where MF(y) is the membership function of the resulting fuzzy set.
Defuzzification, or reduction to clarity. There are several defuzzification methods. For example, the mean center method, or the centroid method:
$$MF\,(y)= \max_i \,(B_i^*\,(y))$$
The geometric meaning of this value is the center of gravity for the MF(y) curve. Figure 6 graphically shows the Mamdani fuzzy inference process for two input variables and two fuzzy rules R1 and R2.
Integration with intelligent paradigms
Hybridization of intellectual information processing methods is the motto under which Western and American researchers passed the 90s. As a result of combining several technologies artificial intelligence a special term appeared - "soft computing" (soft computing), which was introduced by L. Zadeh in 1994. Currently, soft computing combines such areas as: fuzzy logic, artificial neural networks, probabilistic reasoning and evolutionary algorithms. They complement each other and are used in various combinations to create hybrid intelligent systems.
The influence of fuzzy logic turned out to be perhaps the most extensive. Just as fuzzy sets expanded the scope of classical mathematical set theory, fuzzy logic "invaded" almost most Data Mining methods, endowing them with new functionality. The most interesting examples of such associations are given below.
Fuzzy neural networks
Fuzzy neural networks (fuzzy-neural networks) carry out conclusions based on the apparatus of fuzzy logic, however, the parameters of membership functions are tuned using NN learning algorithms. Therefore, to select the parameters of such networks, we use the backpropagation method, which was originally proposed for training a multilayer perceptron. For this, the fuzzy control module is presented in the form of a multilayer network. A fuzzy neural network usually consists of four layers: a fuzzification layer for input variables, a layer for aggregating condition activation values, a layer for aggregating fuzzy rules, and an output layer.
The fuzzy neural network architectures of the ANFIS and TSK types are currently the most widely used. It is proved that such networks are universal approximators.
Fast learning algorithms and the interpretability of the accumulated knowledge - these factors have made today fuzzy neural networks one of the most promising and effective soft computing tools.
Adaptive fuzzy systems
Classical fuzzy systems have the disadvantage that in order to formulate the rules and membership functions, it is necessary to involve experts in a particular subject area, which is not always possible to provide. Adaptive fuzzy systems solve this problem. In such systems, the fuzzy system parameters are selected in the process of learning on experimental data. Algorithms for learning adaptive fuzzy systems are relatively time-consuming and complex compared to learning algorithms for neural networks, and, as a rule, consist of two stages: 1. Generation of linguistic rules; 2. Correction of membership functions. The first problem is related to the enumeration type problem, the second problem is related to optimization in continuous spaces. In this case, a certain contradiction arises: membership functions are needed to generate fuzzy rules, and rules are necessary to carry out fuzzy inference. In addition, when generating fuzzy rules automatically, it is necessary to ensure their completeness and consistency.
A significant part of fuzzy systems training methods uses genetic algorithms. In English literature, this corresponds to a special term - Genetic Fuzzy Systems.
A group of Spanish researchers led by F. Herrera made a significant contribution to the development of the theory and practice of fuzzy systems with evolutionary adaptation.
Fuzzy Queries
Fuzzy queries to databases (fuzzy queries) are a promising direction in modern information processing systems. This tool allows you to formulate queries in natural language, for example: "Display a list of low-cost housing offers close to the city center", which is not possible using the standard query mechanism. For this purpose, fuzzy relational algebra and special extensions have been developed. SQL languages for fuzzy queries. Most of the research in this area belongs to the Western European scientists D. Dubois and G. Prade.
Fuzzy association rules
Fuzzy associative rules are a tool for extracting patterns from databases that are formulated as linguistic statements. Here special concepts of a fuzzy transaction, support and reliability of a fuzzy association rule are introduced.
Fuzzy cognitive maps
Fuzzy cognitive maps were proposed by B. Kosko in 1986 and are used to model causal relationships identified between the concepts of a certain area. Unlike simple cognitive maps, fuzzy cognitive maps are a fuzzy directed graph whose nodes are fuzzy sets. The directed edges of the graph not only reflect the cause-and-effect relationships between concepts, but also determine the degree of influence (weight) of the associated concepts. The active use of fuzzy cognitive maps as a system modeling tool is due to the possibility of a visual representation of the analyzed system and the ease of interpreting cause-and-effect relationships between concepts. The main problems are related to the process of constructing a cognitive map, which is not amenable to formalization. In addition, it is necessary to prove that the constructed cognitive map is adequate to the real simulated system. To solve these problems, algorithms for the automatic construction of cognitive maps based on a data sample have been developed.
Fuzzy clustering
Fuzzy clustering methods, in contrast to precise methods (for example, Kohonen neural networks), allow the same object to belong to several clusters at the same time, but with varying degrees. Fuzzy clustering in many situations is more "natural" than clear, for example, for objects located on the border of clusters. The most common are: the c-means fuzzy self-organization algorithm and its generalization in the form of the Gustafson-Kessel algorithm.
Literature
- Zadeh L. The concept of a linguistic variable and its application to making approximate decisions. – M.: Mir, 1976.
- Kruglov V.V., Dli M.I. Intelligent information systems: computer support for fuzzy logic and fuzzy inference systems. – M.: Fizmatlit, 2002.
- Leolenkov A.V. Fuzzy modeling in MATLAB and fuzzyTECH. - St. Petersburg, 2003.
- Rutkovskaya D., Pilinsky M., Rutkovsky L. Neural networks, genetic algorithms and fuzzy systems. - M., 2004.
- Masalovich A. Fuzzy logic in business and finance. www.tora-centre.ru/library/fuzzy/fuzzy-.htm
- Kosko B. Fuzzy systems as universal approximators // IEEE Transactions on Computers, vol. 43, no. 11, November 1994. - P. 1329-1333.
- Cordon O., Herrera F., A General study on genetic fuzzy systems // Genetic Algorithms in engineering and computer science, 1995. - P. 33-57.
Practical training in the discipline "Expert systems"
Academic year, autumn semester
Lesson 1. Inference in production systems
Example 1 . There is a fragment of the knowledge base of two rules:
P1: If (rest - summer) and (person - active)
then (to go to the mountains)
P2: If (loves - the sun)
then (vacation - summer)
Suppose the system received data - (person - active) and (loves - the sun).
direct withdrawal - Based on the data, get an answer.
1st pass.
Step 1. Try P1, doesn't work (data missing (summer vacation)).
Step 2. We try P2, it works, a fact (summer vacation) enters the database.
2nd pass.
Step 3. We try P1, it works, the goal is activated (to go to the mountains), which acts as a conclusion.
reverse output - confirm the selected target using the available rules and data.
1st pass.
Step 1. Goal - (to go to the mountains): we try P1 - there are no data (rest - in summer), they become a new goal, and the rule is searched for where it is on the right side.
Step 2. Goal (rest - summer): R2 rule confirms the goal and activates it.
2nd pass.
Step 3. We try P1, the desired goal is confirmed.
Example 2 BZ ES characterizing the state on the stock exchange.
· IF Interest rates fall, THEN The price level on the stock exchange is rising.
· IF Interest rates are rising, THEN The price level on the stock exchange falls.
· IF The dollar exchange rate falls, THEN Interest rates are rising.
· IF The dollar exchange rate is rising, THEN Interest rates are falling.
· IF Federal Reserve Interest Rates Fall And Federal Reserve funds added, THEN Interest rates are falling.
The dollar exchange rate is falling. Determine the price level on the stock exchange.
Example 3 Develop rules for the knowledge base of an expert system that advises the director when hiring a new employee, using the one shown in Fig. 1 semantic web. The vertices of the network indicate the coefficients of confidence in the occurrence of an event.
Example 4 Develop rules for the knowledge base of the expert system that advises the client when buying an apartment, using the specified criteria and goals.
Criteria: date of construction of the house; housing condition (need for repair); the area where the apartment is located; ecological situation in the area; distance from a public transport stop; the cost of the apartment.
Goals: the apartment is good and fully satisfies you; the apartment is satisfactory, although it has a number of shortcomings; the apartment doesn't suit you.
Example 5 Develop a decision tree for the knowledge base of an expert system advising a customer when buying a car, using the specified criteria and goals.
Criteria: brand of car (eg VAZ, Audi, BMW, Renault, Subaru, Honda), year of manufacture, price, number of gears, engine size, number of doors, fuel consumption.
Goals: car choice.
Lesson 2. Knowledge processing using fuzzy set theory
Option 1
Example 1. Development of a fuzzy inference system (FIS)
It is necessary to assess the degree investment attractiveness specific business project based on discount rate and payback period data. The solution of the problem consists of the following steps.
Stage 1. Let's create a START structure: two inputs, Mamdani fuzzy inference mechanism, one output. We declare the first variable as discount, and second - period, which will respectively represent the discount rate and the payback period of the business project. The name of the output variable, on the basis of which a decision is made on the degree of investment attractiveness of a business project, is given as rate.
Stage 2. Each input and output variable will be assigned a set of membership functions (FC). For discount define the range of the base variable from 5 to 50 (unit of measurement - percentage). We select the same range for its display. Let's add three FPs, the type of which is triangular fuzzy numbers (trimf). For the linguistic variable "discount rate" discount define the values of the terms: “small”, “medium” and “large” ( small, medium, large).
For a linguistic variable period the range of the base variable is defined equal to (unit of measurement - months), terms of the variable with names: “short”, “usual”, “long” payback period (s short, normal, long) three FPs of the Gaussian type (gaussmf). For the output variable rate, we define: the range of the base variable is , the terms “bad”, “normal”, “good” (bad, normal, good) are described by three FPs of the type trimf
Stage 3. Let's define a set of rules of the form IF…THEN, which define the relationship between input variables and output variables (do it yourself). For example, the rule
IF discount=small And period-short THEN rate=good
Stage 4. Formation of recommendations by an expert system. Suppose we want to determine the degree of investment attractiveness of the project. In order to use the rules of the knowledge base, it is necessary to have information about the discount rate and the payback period.
Exercise: determine the degree of investment attractiveness of the project with the data on the remaining discounting discount=15%, payback period of a business project period= 10 months.
The concept of fuzzy inference is central to fuzzy logic and fuzzy control theory. Speaking about fuzzy logic in control systems, we can give the following definition of a fuzzy inference system.
Fuzzy inference system is the process of obtaining fuzzy conclusions about the required control of an object based on fuzzy conditions or prerequisites, which are information about the current state of the object.
This process combines all the basic concepts of fuzzy set theory: membership functions, linguistic variables, fuzzy implication methods, etc. The development and application of fuzzy inference systems includes a number of stages, the implementation of which is carried out on the basis of the provisions of fuzzy logic considered earlier (Fig. 2.18).
Fig.2.18. Diagram of the process of fuzzy inference in fuzzy ACS
The rule base of fuzzy inference systems is designed to formally represent the empirical knowledge of experts in a particular subject area in the form fuzzy production rules. Thus, the base of fuzzy production rules of a fuzzy inference system is a system of fuzzy production rules that reflects the knowledge of experts about the methods of managing an object in various situations, the nature of its functioning in various conditions, etc., i.e. containing formalized human knowledge.
Fuzzy production rule is an expression of the form:
(i):Q;P;A═>B;S,F,N,
Where (i) is the name of the fuzzy production, Q is the scope of the fuzzy production, P is the applicability condition for the core of the fuzzy production, A═>B is the core of the fuzzy production, in which A is the condition of the core (or antecedent), B is the conclusion of the core (or consequent), ═> - a sign of logical sequence or following, S - a method or method for determining the quantitative value of the degree of truth of the conclusion of the core, F - the coefficient of certainty or confidence of fuzzy production, N - postconditions of production.
The scope of fuzzy products Q describes explicitly or implicitly the subject area of knowledge that a separate product represents.
The applicability condition of the production kernel P is a logical expression, usually a predicate. If it is present in the production, then the activation of the core of the production becomes possible only if this condition is true. In many cases, this product element can be omitted or introduced into the core of the product.
The kernel A═>B is the central component of the fuzzy production. It can be presented in one of the more common forms: "IF A THEN B", "IF A THEN B"; where A and B are some expressions of fuzzy logic, which are most often represented in the form of fuzzy statements. Compound logical fuzzy statements can also be used as expressions, i.e. elementary fuzzy statements connected by fuzzy logical connectives, such as fuzzy negation, fuzzy conjunction, fuzzy disjunction.
S is a method or method for determining the quantitative value of the degree of truth of the conclusion B based on the known value of the degree of truth of the condition A. This method defines a fuzzy inference scheme or algorithm in production fuzzy systems and is called composition method or activation method.
The confidence factor F expresses a quantitative assessment of the degree of truth or the relative weight of fuzzy products. The confidence factor takes its value from the interval and is often called the weighting factor of the fuzzy production rule.
The fuzzy production postcondition N describes the actions and procedures that must be performed in the case of the implementation of the production core, i.e. obtaining information about the truth of B. The nature of these actions can be very different and reflect the computational or other aspect of the production system.
A consistent set of fuzzy production rules forms fuzzy production system. Thus, a fuzzy production system is a domain-specific list of fuzzy production rules “IF A THEN B”.
The simplest option fuzzy production rule:
RULE<#>: IF β 1 "IS ά 1" THEN "β 2 IS ά 2"
RULE<#>: IF " β 1 IS ά 1 " THEN " β 2 display:block IS ά 2 ".
The antecedent and consequent of the fuzzy production core can be complex, consisting of the connectives “AND”, “OR”, “NOT”, for example:
RULE<#>: IF "β 1 IS ά" AND "β 2 IS NOT ά" THEN "β 1 IS NOT β 2"
RULE<#>: IF « β 1 IS ά » AND « β 2 IS NOT ά » THEN « β 1 IS NOT β 2 ».
Most often, the base of fuzzy production rules is presented in the form of a structured text that is consistent with respect to the used linguistic variables:
RULE_1: IF "Condition_1" THEN "Conclusion_1" (F 1 t),
RULE_n: IF "Condition_n" THEN "Conclusion_n" (F n),
where F i ∈ is the certainty factor or the weighting factor of the corresponding rule. The consistency of the list means that only simple and compound fuzzy statements connected by binary operations “AND”, “OR” can be used as conditions and conclusions of the rules, while in each of the fuzzy statements the membership functions of the term set values for each linguistic variable must be defined. As a rule, the membership functions of individual terms are represented by triangular or trapezoidal functions. The following abbreviations are commonly used to name individual terms.
Table 2.3.

Example. There is a bulk tank (tank) with a continuous controlled flow of liquid and a continuous uncontrolled flow of liquid. The rule base of the fuzzy inference system, corresponding to the expert's knowledge of which liquid inflow should be chosen so that the liquid level in the tank remains average, will look like this:
| RULE<1>: | And "fluid consumption is large" | TO "fluid inflow | large medium small | »; | |
| RULE<2>: | IF "liquid level is low" | And "fluid consumption is average" | TO "fluid inflow | large medium small | »; |
| RULE<3>: | IF "liquid level is low" | And "fluid consumption is small" | TO "fluid inflow | large medium small | »; |
| RULE<4>: | And "fluid consumption is large" | TO "fluid inflow | large medium small | »; | |
| RULE<5>: | IF "liquid level is medium" | And "fluid consumption is average" | TO "fluid inflow | large medium small | »; |
| RULE<6>: | IF "liquid level is medium" | And "fluid consumption is small" | TO "fluid inflow | large medium small | »; |
| RULE<7>: | And "fluid consumption is large" | TO "fluid inflow | large medium small | »; | |
| RULE<8>: | IF "liquid level is high" | And "fluid consumption is average" | TO "fluid inflow | large medium small | »; |
| RULE<9>: | IF "liquid level is high" | And "fluid consumption is small" | TO "fluid inflow | large medium small | ». |
Using the designations ZP - "small", PM - "medium", PB - "large", this base fuzzy production rules can be represented in the form of a table, in the nodes of which there are corresponding conclusions about the required fluid inflow:
Table 2.4.
|
||||||||||||||||||||
Example. The formalization of the description of the liquid level in the tank and the liquid flow rate was carried out using linguistic variables, the tuple of which contains three fuzzy variables each, corresponding to the concepts of small, medium and of great importance the corresponding physical quantities, the membership functions of which are presented in Fig. 2.19.
Triangular Trapezoidal Z-linear S-linear
Triangular Trapezoidal Z-linear S-linear
Current level:
Triangular Trapezoidal Z-linear S-linear
Triangular Trapezoidal Z-linear S-linear
Triangular Trapezoidal Z-linear S-linear
Current consumption:
Fig.2.19. Membership functions of tuples of linguistic variables corresponding to fuzzy concepts of small, medium, large level and fluid flow, respectively
If the current level and flow rate of the liquid are 2.5 m and 0.4 m 3 /sec, respectively, then with fuzzification we obtain the degrees of truth of elementary fuzzy statements:
- "liquid level is small" - 0.75;
- "liquid level is average" - 0.25;
- "liquid level is high" - 0.00;
- "liquid flow rate is small" - 0.00;
- “fluid consumption is average” - 0.50;
- “Large fluid flow” - 1.00.
Aggregation is a procedure for determining the degree of truth of conditions for each of the rules of the fuzzy inference system. In this case, the values of the membership functions of the terms of linguistic variables obtained at the stage of fuzzification, which make up the above conditions (antecedents) of the kernels of fuzzy production rules, are used.
If the condition of a fuzzy production rule is a simple fuzzy statement, then the degree of its truth corresponds to the value of the membership function of the corresponding term of the linguistic variable.
If the condition represents a compound statement, then the degree of truth of the compound statement is determined on the basis of the known truth values of its constituent elementary statements using previously introduced fuzzy logical operations in one of the predetermined bases.
For example, taking into account the truth values of elementary propositions obtained as a result of fuzzification, the degree of truth of the conditions for each composite rule of the fuzzy inference system for controlling the liquid level in the tank, in accordance with the definition of the fuzzy logical "AND" of two elementary propositions A, B: T(A ∩ B)=min(T(A);T(B)) , will be next.
RULE<1>: antecedent - “liquid level is small” AND “liquid flow is large”; degree of truth
antecedent min(0.75 ;1.00 )=0.00 .
RULE<2>: antecedent - "liquid level is small" AND "liquid flow is medium"; degree of truth
antecedent min(0.75 ;0.50 )=0.00 .
RULE<3>: antecedent - “liquid level is small” AND “liquid flow is small”, degree of truth
antecedent min(0.75 ;0.00 )=0.00 .
RULE<4>: antecedent - “fluid level is medium” AND “liquid flow is large”, degree of truth
antecedent min(0.25 ;1.00 )=0.00 .
RULE<5>: antecedent - “fluid level is average” AND “fluid flow is average”, degree of truth
antecedent min(0.25 ;0.50 )=0.00 .
RULE<6>: antecedent - “fluid level is medium” AND “liquid flow is small”, degree of truth
antecedent min(0.25 ;0.00 )=0.00 .
RULE<7>: antecedent - “liquid level is large” AND “liquid flow is large”, degree of truth
antecedent min(0.00 ;1.00 )=0.00 .
RULE<8>: antecedent - “high liquid level” AND “medium liquid flow”, degree of truth
antecedent min(0.00 ;0.50 )=0.00 .
RULE<9>: antecedent - “liquid level is large” AND “liquid flow is small”, degree of truth
antecedent min(0.00 ;0.00 )=0.00 .
|
||||||||||||||||||||
Activation in fuzzy inference systems, it is a procedure or process of finding the degree of truth of each of the elementary logical statements (subconclusions) that make up the consequents of the kernels of all fuzzy production rules. Since the conclusions are made about the output linguistic variables, the degrees of truth of elementary sub-conclusions are associated with elementary membership functions during activation.
If the conclusion (consequent) of a fuzzy production rule is a simple fuzzy statement, then the degree of its truth is equal to the algebraic product of the weight coefficient and the degree of truth of the antecedent of this fuzzy production rule.
If the conclusion is a compound statement, then the degree of truth of each of the elementary statements is equal to the algebraic product of the weight coefficient and the degree of truth of the antecedent of the given fuzzy production rule.
If the weight coefficients of the production rules are not explicitly specified at the stage of generating the rule base, then their default values are equal to one.
The membership functions μ (y) of each of the elementary subconclusions of the consequents of all production rules are found using one of the fuzzy composition methods:
- min-activation – μ (y) = min ( c ; μ (x) ) ;
- prod-activation - μ (y) =c μ (x) ;
- average-activation – μ (y) =0.5(c + μ (x)) ;
Where μ (x) and c are, respectively, the membership functions of the terms of linguistic variables and the degree of truth of fuzzy statements that form the corresponding consequences (consequences) of the kernels of fuzzy production rules.
Example. If the formalization of the description of the fluid inflow in the tank is carried out using a linguistic variable, the tuple of which contains three fuzzy variables corresponding to the concepts of small, medium and large values of the fluid inflow, the membership functions of which are shown in Fig. 2.19, then for the production rules of the fuzzy inference system for control the liquid level in the tank by changing the liquid inflow, the membership functions of all subconclusions with min activation will look like this (Fig. 2.20 (a), (b)).
Fig.2.20(a). Membership function of a tuple of linguistic variables corresponding to the fuzzy concepts of small, medium, large liquid inflow into the tank and min-activation of all subconclusions of the fuzzy production rules of the liquid level control system in the tank
Fig.2.20(b). Membership function of a tuple of linguistic variables corresponding to the fuzzy concepts of small, medium, large liquid inflow into the tank and min-activation of all subconclusions of the fuzzy production rules of the liquid level control system in the tank
Accumulation(or storage) in fuzzy inference systems is the process of finding the membership function for each of the output linguistic variables. The purpose of accumulation is to combine all degrees of truth of the subconclusions to obtain a membership function for each of the output variables. The accumulation result for each output linguistic variable is defined as the union of fuzzy sets of all subconclusions of the fuzzy rule base with respect to the corresponding linguistic variable. The union of membership functions of all subconclusions is usually carried out classically ∀ x ∈ X μ A ∪ B (x) = max ( μ A (x) ; μ B (x) ) (max-union), the operations can also be used:
- algebraic union ∀ x ∈ X μ A+B x = μ A x + μ B x - μ A x ⋅ μ B x ,
- boundary union ∀ x ∈ X μ A B x = min( μ A x ⋅ μ B x ;1) ,
- drastic union ∀ x ∈ X μ A ∇ B (x) = ( μ B (x) , e c l and μ A (x) = 0, μ A (x) , e c l and μ B (x) = 0 , 1, in other cases,
- and also λ-sums ∀ x ∈ X μ (A+B) x = λ μ A x +(1-λ) μ B x ,λ∈ .
Example. For the production rules of the fuzzy inference system for controlling the liquid level in the tank by changing the liquid inflow, the membership function of the linguistic variable "liquid inflow", obtained as a result of the accumulation of all subconclusions with max-union, will look like this (Fig. 2.21).
Fig. 2.21 Membership function of the linguistic variable "fluid inflow"
Defuzzification in fuzzy inference systems, this is the process of transition from the membership function of the output linguistic variable to its clear (numerical) value. The purpose of defuzzification is to use the results of the accumulation of all output linguistic variables to obtain quantitative values for each output variable that is used by devices external to the fuzzy inference system (actuators of intelligent ACS).
The transition from the membership function μ (x) of the output linguistic variable obtained as a result of accumulation to the numerical value y of the output variable is performed by one of the following methods:
- center of gravity method(Centre of Gravity) is to calculate area centroid y = ∫ x min x max x μ (x) d x ∫ x min x max μ (x) d x , where [ x max ; x min ] is the carrier of the fuzzy set of the output linguistic variable; (in Fig. 2.21 the result of defuzzification is indicated by the green line)
- center area method(Centre of Area) consists in calculating the abscissa y dividing the area bounded by the membership function curve μ (x), the so-called area bisector ∫ x min y μ (x) d x = ∫ y x max μ (x) d x; (in Fig. 2.21 the result of defuzzification is indicated by a blue line)
- left modal value method y= x min ;
- right modal value method y=xmax
Example. For the production rules of the fuzzy inference system for controlling the liquid level in the tank by changing the liquid inflow, the defuzzification of the membership function of the linguistic variable "liquid inflow" (Fig. 2.21) leads to the following results:
- center of gravity method y= 0.35375 m 3 /sec;
- method of the center of the area y \u003d 0, m 3 / s
- left modal value method y= 0.2 m 3 /sec;
- right modal value method y= 0.5 m 3 /sec
The considered stages of fuzzy inference can be implemented in an ambiguous way: aggregation can be carried out not only in the basis of Zadeh's fuzzy logic, activation can be carried out by various methods of fuzzy composition, at the accumulation stage, the union can be carried out in a way different from max-combining, defuzzification can also be carried out by various methods. Thus, the choice of specific ways to implement individual stages of fuzzy inference determines one or another fuzzy inference algorithm. At present, the question of criteria and methods for choosing a fuzzy inference algorithm, depending on a specific technical problem, remains open. At the moment, the following algorithms are most often used in fuzzy inference systems.
Algorithm Mamdani (Mamdani) found application in the first fuzzy systems automatic control. It was proposed in 1975 by the English mathematician E. Mamdani to control a steam engine.
- The formation of the rules base of the fuzzy inference system is carried out in the form of an ordered agreed list of fuzzy production rules in the form “IF A THEN B ”, where the antecedents of the kernels of the fuzzy production rules are built using logical connectives “AND”, and the consequents of the kernels of the fuzzy production rules are simple.
- Fuzzification of input variables is carried out in the manner described above, just as in the general case of constructing a fuzzy inference system.
- Aggregation of subconditions of fuzzy production rules is carried out using the classical fuzzy logical operation "AND" of two elementary statements A, B: T(A ∩ B) = min( T(A);T(B) ) .
- Activation of subconclusions of fuzzy production rules is carried out by the min-activation method μ (y) = min(c; μ (x) ) , where μ (x) and c are, respectively, the membership functions of terms of linguistic variables and the degree of truth of fuzzy statements that form the corresponding consequences (consequent ) kernels of fuzzy production rules.
- The accumulation of subconclusions of fuzzy production rules is carried out using the classical fuzzy logic max-union of membership functions ∀ x ∈ X μ A B x = max( μ A x ; μ B x ) .
- Defuzzification is carried out using the center of gravity or center of area method.
For example, the case of tank level control described above corresponds to the Mamdani algorithm if, at the defuzzification stage, a clear value of the output variable is sought by the center of gravity or area method: y= 0.35375 m 3 /sec or y= 0.38525 m 3 /sec, respectively.
Algorithm Tsukamoto (Tsukamoto) formally looks like this.
- Aggregation of subconditions of fuzzy production rules is carried out similarly to the Mamdani algorithm using the classical fuzzy logical operation "AND" of two elementary statements A, B: T(A ∩ B) = min( T(A);T(B) )
- The activation of subconclusions of fuzzy production rules is carried out in two stages. At the first stage, the degrees of truth of conclusions (consequences) of fuzzy production rules are found similarly to the Mamdani algorithm, as an algebraic product of the weight coefficient and the degree of truth of the antecedent of this fuzzy production rule. At the second stage, in contrast to the Mamdani algorithm, for each of the production rules, instead of constructing the membership functions of subconclusions, the equation μ (x) = c is solved and a clear value ω of the output linguistic variable is determined, where μ (x) and c are, respectively, the membership functions of the linguistic terms variables and the degree of truth of fuzzy statements that form the corresponding consequences (consequences) of the kernels of fuzzy production rules.
- At the defuzzification stage, for each linguistic variable, a transition is made from a discrete set of crisp values ( w 1 . . . w n ) to a single crisp value according to the discrete analogue of the center of gravity method y = ∑ i = 1 n c i w i ∑ i = 1 n c i ,
where n is the number of rules of fuzzy production, in the subconclusions of which this linguistic variable appears, c i is the degree of truth of the subconclusion of the production rule, w i is the clear value of this linguistic variable obtained at the activation stage by solving the equation μ (x) = c i , i.e. μ (w i) = c i , and μ (x) represents the membership function of the corresponding term of the linguistic variable.
For example, the Tsukamoto algorithm is implemented if, in the tank level control case described above:
- at the activation stage, use the data in Fig. 2.20 and graphically solve the equation μ (x) = c i for each production rule, i.e. find pairs of values (c i , w i): rule1 - (0.75 ; 0.385), rule2 - (0.5 ; 0.375), rule3- (0 ; 0), rule4 - (0.25 ; 0.365), rule5 - ( 0.25 ; 0.365),
rule6 - (0 ; 0), rule7 - (0 ; 0), rule7 - (0 ; 0), rule8 - (0 ; 0), rule9 - (0 ; 0), there are two roots for the fifth rule; - at the stage of defuzzification for the linguistic variable "fluid inflow" to carry out the transition from a discrete set of clear values ( ω 1 . . . ω n ) to a single clear value according to the discrete analogue of the center of gravity method y = ∑ i = 1 n c i w i ∑ i = 1 n c i , y = 0.35375 m 3 / s
Larsen's algorithm formally looks like this.
- The formation of the rule base of the fuzzy inference system is carried out similarly to the Mamdani algorithm.
- Fuzzification of input variables is carried out similarly to the Mamdani algorithm.
- Activation of subconclusions of fuzzy production rules is carried out by the prod-activation method, μ (y)=c μ (x) , where μ (x) and c are, respectively, the membership functions of terms of linguistic variables and the degree of truth of fuzzy statements that form the corresponding consequences (consequents) of fuzzy kernels production rules.
- The accumulation of subconclusions of the fuzzy production rules is carried out similarly to the Mamdani algorithm using the classical fuzzy logic max-union of membership functions T(A ∩ B) = min( T(A);T(B) ) .
- Defuzzification is carried out by any of the methods discussed above.
For example, Larsen's algorithm is implemented if, in the case of tank level control described above, at the activation stage, the membership functions of all subconclusions are obtained according to prod-activation (Fig. 2.22 (a), (b)), then the membership function of the linguistic variable "fluid inflow", obtained in the result of the accumulation of all subconclusions with max-unification will look like this (Fig. 2.22(b)), and the defuzzification of the membership function of the linguistic variable "fluid inflow" leads to the following results: center of gravity method y= 0.40881 m 3 /sec, area center method y \u003d 0.41017 m 3 / s
Fig. 2.22(a) Prod-activation of all subconclusions of the fuzzy production rules of the liquid level control system in the tank
Fig. 2.22(b) Prod-activation of all subconclusions of the fuzzy production rules of the liquid level control system in the tank and the membership function of the linguistic variable "liquid inflow" obtained by max-union
,Sugeno algorithm as follows.
- The rule base of the fuzzy inference system is formed in the form of an ordered agreed list of fuzzy production rules in the form “IF A AND B THEN w = ε 1 a + ε 2 b ”, where the antecedents of the cores of the fuzzy production rules are built from two simple fuzzy statements A, B with using logical connectives "AND", a and b are clear values of input variables corresponding to statements A and B, respectively, ε 1 and ε 2 are weight coefficients that determine the coefficients of proportionality between the clear values of input variables and the output variable of the fuzzy inference system, w is a clear the value of the output variable, defined in the conclusion of the fuzzy rule, as a real number.
- Fuzzification of the input variables that define statements and is carried out similarly to Mamdani's algorithm.
- Aggregation of subconditions of fuzzy production rules is carried out similarly to the Mamdani algorithm using the classical fuzzy logical operation "AND" of two elementary statements A, B: T(A ∩ B) = min( T(A);T(B) ) .
- “Activation of subconclusions of fuzzy production rules is carried out in two stages. At the first stage, the degrees of truth c of the conclusions (consequences) of the fuzzy production rules that associate the output variable with real numbers are found similarly to the Mamdani algorithm, as an algebraic product of the weight coefficient and the degree of truth of the antecedent of this fuzzy production rule. At the second stage, in contrast to Mamdani's algorithm, for each of the production rules, instead of constructing the membership functions of subconclusions in an explicit form, a clear value of the output variable w = ε 1 a + ε 2 b is found. Thus, each i-th production rule is assigned a point (c i w i) , where c i is the degree of truth of the production rule, w i is the exact value of the output variable defined in the consequent of the production rule.
- The accumulation of the conclusions of the fuzzy production rules is not carried out, since at the activation stage discrete sets of crisp values have already been obtained for each of the output linguistic variables.
- Defuzzification is carried out as in the Tsukamoto algorithm. For each linguistic variable, a transition is made from a discrete set of crisp values ( w 1 . . . w n ) to a single crisp value according to the discrete analog of the center of gravity method y = ∑ i = 1 n c i w i ∑ i = 1 n c i , where n is the number of fuzzy production rules, in the subconclusions of which this linguistic variable appears, c i is the degree of truth of the subconclusion of the production rule, w i is the clear value of this linguistic variable, established in the consequent of the production rule.
For example, the Sugeno algorithm is implemented if, in the case of liquid level control in the tank described above, at the stage of forming the rule base of the fuzzy inference system, the rules are set based on the fact that while maintaining a constant liquid level, the numerical values of the inflow w and flow rate b must be equal to each other ε 2 =1 , and the filling rate of the tank is determined by the corresponding change in the proportionality coefficient ε 1 between the inflow w and the liquid level a. In this case, the rule base of the fuzzy inference system, corresponding to the expert’s knowledge of which fluid inflow w = ε 1 a + ε 2 b should be chosen in order for the liquid level in the tank to remain average, will look like this:
RULE<1>: IF “liquid level is small” AND “liquid flow is large” THEN w=0.3a+b;
RULE<2>: IF “liquid level is low” AND “liquid flow is medium” THEN w=0.2a+b;
RULE<3>: IF “liquid level is low” AND “liquid flow is small” THEN w=0.1a+b ;
RULE<4>: IF “liquid level is medium” AND “liquid flow is large” THEN w=0.3a+b;
RULE<5>: IF “liquid level is average” AND “liquid flow is average” THEN w=0.2a+b;
RULE<6>: IF “liquid level is medium” AND “liquid flow is small” THEN w=0.1a+b;
RULE<7>: IF “liquid level is large” AND “liquid flow is large” THEN w=0.4a+b;
RULE<8>: IF “liquid level is large” AND “liquid flow is average” THEN w=0.2a+b;
RULE<9>: IF “liquid level is large” AND “liquid flow is small” THEN w=0.1a+b.
At the previously considered current level and flow rate a= 2.5 m and b= 0.4 m 3 /sec, respectively, as a result of fuzzification, aggregation and activation, taking into account the explicit definition of clear values of the output variable in the consequents of production rules, we obtain pairs of values (c i w i) : rule1 - (0.75 ; 1.15), rule2 - (0.5 ; 0.9), rule3- (0 ; 0.65), rule4 - (0.25 ; 1.15), rule5 - (0.25 ; 0.9), rule6 - (0 ; 0.65), rule7 - (0 ; 0), rule7 - (0 ; 1.14), rule8 - (0 ; 0.9), rule9 - (0 ; 0, 65). At the stage of defuzzification for the linguistic variable “fluid inflow”, the transition from a discrete set of clear values ( w 1 . . . w n ) to a single clear value according to the discrete analogue of the center of gravity method y = ∑ i = 1 n c i w i ∑ i = 1 n c i , y= 1.0475 m 3 /sec
Simplified Fuzzy Inference Algorithm is formally specified in exactly the same way as the Sugeno algorithm, only when explicitly specifying clear values in the consequents of production rules, instead of the relation w= ε 1 a+ ε 1 b, the direct value of w is explicitly specified. Thus, the formation of the rule base of the fuzzy inference system is carried out in the form of an ordered consistent list of fuzzy production rules in the form “IF A AND B THEN w=ε ”, where the antecedents of the kernels of the fuzzy production rules are built from two simple fuzzy statements A, B using logical connectives "AND", w - a clear value of the output variable, defined for each conclusion of the i -th rule, as a real number ε i .
For example, A simplified fuzzy inference algorithm is implemented if, in the case of liquid level control in the tank described above, at the stage of forming the rule base of the fuzzy inference system, the rules are specified as follows:
RULE<1>: IF “liquid level is small” AND “liquid flow is large” THEN w=0.6;
RULE<2>: IF “liquid level is low” AND “liquid flow is average” THEN w=0.5;
RULE<3>: IF “liquid level is low” AND “liquid flow is small” THEN w=0.4;
RULE<4>: IF “liquid level is medium” AND “liquid flow is large” THEN w=0.5;
RULE<5>: IF “liquid level is average” AND “liquid flow is average” THEN w=0.4;
RULE<6>: IF “liquid level is medium” AND “liquid flow is small” THEN w=0.3;
RULE<7>: IF “liquid level is large” AND “liquid flow is large” THEN w=0.3;
RULE<8>: IF “liquid level is large” AND “liquid flow is average” THEN w=0.2;
RULE<9>: IF “liquid level is large” AND “liquid flow is small” THEN w=0.1.
With the current level and flow rate already considered and, accordingly, as a result of fuzzification, aggregation and activation, taking into account the explicit definition of clear values of the output variable in the consequents of the production rules, we obtain pairs of values (c i w i) : rule1 - (0.75 ; 0.6), rule2 - (0.5 ; 0.5), rule3 - (0 ; 0.4), rule4 - (0.25 ; 0.5), rule5 - (0.25 ; 0.4), rule6 - (0 ; 0.3),
rule7 - (0 ; 0.3), rule7 - (0 ; 0.3), rule8 - (0 ; 0.2), rule9 - (0 ; 0.1) . At the stage of defuzzification for the linguistic variable “fluid inflow”, the transition from a discrete set of clear values ( w 1 . . . w n ) to a single clear value according to the discrete analogue of the center of gravity method y = ∑ i = 1 n c i w i ∑ i = 1 n c i , y= 1.0475 m 3 / s, y \u003d 0.5 m 3 / s
Using fuzzy sets, one can formally define inexact and ambiguous concepts, such as “high temperature” or “big city”. To formulate the definition of a fuzzy set, it is necessary to set the so-called area of reasoning. For example, when we estimate the speed of a car, we will limit ourselves to the range X = , where Vmax is the maximum speed that the car can reach. It must be remembered that X is a crisp set.
Basic concepts
fuzzy set A in some non-empty space X is the set of pairsWhere ![]()
- membership function of the fuzzy set A. This function assigns to each element x the degree of its membership in the fuzzy set A.
Continuing the previous example, consider three imprecise formulations:
- "Low vehicle speed";
- "Average vehicle speed";
- "High speed of the car."
The figure shows fuzzy sets corresponding to the above formulations using membership functions. 
At a fixed point X=40km/h. the membership function of the fuzzy set "low vehicle speed" takes the value 0.5. The membership function of the fuzzy set "average car speed" takes the same value, while for the set "high car speed" the value of the function at this point is 0.
A function T of two variables T: x -> is called T-norm, if:
- is non-increasing with respect to both arguments: T(a, c)< T(b, d) для a < b, c < d;
- is commutative: T(a, b) = T(b, a);
- satisfies the connection condition: T(T(a, b), c) = T(a, T(b, c));
- satisfies the boundary conditions: T(a, 0) = 0, T(a, 1) = a.
Direct fuzzy inference
Under fuzzy inference is understood as a process in which some consequences, possibly also fuzzy, are obtained from fuzzy premises. Approximate reasoning underlies a person's ability to understand natural language, read handwriting, play games that require mental effort, and in general, make decisions in a complex and incompletely defined environment. This ability to reason in qualitative, imprecise terms distinguishes human intelligence from the intelligence of a computer.The main inference rule in traditional logic is the modus ponens rule, according to which we judge the truth of statement B by the truth of statements A and A -> B. For example, if A is the statement “Stepan is an astronaut”, B is the statement “Stepan flies into space” , then if the statements "Stepan is an astronaut" and "If Stepan is an astronaut, then he flies into space" are true, then the statement "Stepan flies into space" is also true.
However, unlike traditional logic, the main tool of fuzzy logic will not be the modus ponens rule, but the so-called compositional inference rule, a very special case of which is the modus ponens rule.
Suppose there is a curve y=f(x) and the value x=a is given. Then from the fact that y=f(x) and x=a we can conclude that y=b=f(a). 
We now generalize this process by assuming that a is an interval and f(x) is a function whose values are intervals. In this case, to find the interval y=b corresponding to the interval a, we first construct a set a" with base a and find its intersection I with the curve whose values are intervals. Then we project this intersection onto the OY axis and obtain the desired value of y in interval b. Thus, from the fact that y=f(x) and x=A is a fuzzy subset of the OX axis, we get the value of y as a fuzzy subset B of the OY axis.
Let U and V be two universal sets with base variables u and v, respectively. Let A and F be fuzzy subsets of the sets U and U x V. Then the compositional inference rule states that the fuzzy set B = A * F follows from the fuzzy sets A and F.
Let A and B be fuzzy statements and m(A), m(B) be the membership functions corresponding to them. Then the implication A -> B will correspond to some membership function m(A -> B). By analogy with traditional logic, it can be assumed that
Then
However, this is not the only generalization of the implication operator; there are others.
Implementation
To implement the direct fuzzy inference method, we need to choose an implication operator and a T-norm.Letting T-norm be the minimum function:
and the implication operator will be the Gödel function:
The input data will contain knowledge (fuzzy sets) and rules (implications), for example:
A = ((x1, 0.0), (x2, 0.2), (x3, 0.7), (x4, 1.0)).
B = ((x1, 0.7), (x2, 0.4), (x3, 1.0), (x4, 0.1)).
A => B.
The implication will be represented as a Cartesian matrix, each element of which is calculated using the selected implication operator (in this example, the Gödel function):
- def compute_impl(set1, set2):
- """
Computing implication
"""- relation = ()
- for i in set1.items():
- relation[i] = ()
- for j in set2.items():
- v1 = set1.value(i)
- v2 = set2.value(j)
- relation[i][j] = impl(v1, v2)
- return relation
For the data above it would be:
Conclusion:
A => B.
x1 x2 x3 x4
x1 1.0 1.0 1.0 1.0
x2 1.0 1.0 1.0 0.1
x3 1.0 0.4 1.0 0.1
x4 0.7 0.4 1.0 0.1
- def conclusion (set, relation):
- """
Conclusion
"""- conl_set =
- for i in relation:
- l =
- for j in relation[i]:
- v_set = set.value(i)
- v_impl = relation[i][j]
- l.append(t_norm(v_set, v_impl))
- value = max(l)
- conl_set. append((i, value))
- return conl_set
Result:
B" = ((x1, 1.0), (x2, 0.7), (x3, 1.0), (x4, 0.7)).
Sources
- Rutkovskaya D., Pilinsky M., Rutkovsky L. Neural networks, genetic algorithms and fuzzy systems: Per. from Polish. I. D. Rudinsky. - M.: Hot line - Telecom, 2006. - 452 p.: ill.
- Zadeh L. A. Fuzzy Sets, Information and Control, 1965, vol. 8, s. 338-353
Fuzzy sets. linguistic variable. Fuzzy logic. Fuzzy conclusion. composition rule of inference.
(Abstract)
The concept of a fuzzy set (NS) is based on the notion that elements of a certain set that have a common property can have different degrees of degeneracy of this property and, consequently, different degrees of belonging to this property.
Let U be some set. A fuzzy set à in U is a collection of pairs of the form ((µ à (u), u)), where u U, µ à .
The value µ Г is called the degree of membership of the object in the fuzzy set U.
µ Ã : U
µ Ã is called the membership function.
An example of fuzzy sets is the age of people (Fig. 19.1).

By analogy with traditional set theory, the NM Theory defines the following operations:
Union:
![]() , where
, where ![]()
Enumeration:
![]() ,
,
Addition:
Algebraic product:
![]() , where
, where
An n-ary fuzzy relation defined on sets is a fuzzy subset of Cartesian products ![]()
Since a fuzzy relation is a set, all operations defined for fuzzy sets are valid for it. In practical applications of the theory of fuzzy sets, the composition of fuzzy relations plays an important role.
Composition of fuzzy relations
Let 2 two-place fuzzy relations be given:
The composition of fuzzy relations is determined by the following expression:
 Membership Degrees of Specific Expressions
Membership Degrees of Specific Expressions



Linguistic variable - is a five X - variable name (age), U - basic set (0 ... 150), T (x) - term of the set. Sets of linguistic meanings (young, middle-aged, elderly, old). Each linguistic value is a label of a fuzzy set defined on U. G is a syntactic rule that generates the linguistic value of the variable X (very young, very old). M is a semantic rule that assigns to each linguistic value a fuzzy subset of the base set, that is, a membership function.
A fuzzy statement is a statement regarding which at a given moment in time it is possible to judge the degree of its truth or falsity. Truth takes a value in the interval . A fuzzy statement that does not allow division into simpler ones is called elementary.
A fuzzy statement built on elementary ones using logical connectives is called a compound fuzzy statement. Logical connectives correspond to operations on the truth of fuzzy statements. - the degree of truth of specific statements.
2)
![]()
Thus, the algebra of fuzzy sets is isomorphic to the algebra of fuzzy propositions.
4) implication operation
Several definitions have been proposed for the implication operation in fuzzy logic. Main:
1)
![]()
2)
![]()
3)
![]()
5) Equivalence
An n-place fuzzy predicate defined on the sets U 1 , U 2 ,…,U n is an expression containing the subject variables of these sets and turning into fuzzy statements when the subject variables are replaced by elements of the sets U 1 , U 2 ,…,U n .
Let U 1 , U 2 ,…,U n be basic sets of linguistic variables, and let the yen of linguistic variables act as symbols of subject variables. Then examples of fuzzy predicates are:
"pressure in the cylinder is low" - one-place predicate
“the temperature in the boiler is much higher than the temperature in the heat exchanger” - a two-place predicate.

If U k \u003d 1.5, therefore "pressure in the boiler is low" \u003d 0.7
In the construction and implementation of fuzzy algorithms, the compositional inference rule plays an important role.
Let be a fuzzy mapping
A fuzzy subset of the universe U then generates in V a fuzzy subset

![]()
the compositional inference rule is the basis for constructing a logical inference in fuzzy logic.
Let a fuzzy statement be given, where and are fuzzy sets. Let also some statement (close to A, but not identical to it) be given.
In classical logic, the Modus Ponens inference rule is widely used
This rule is generalized to the case of fuzzy logic as follows:
Let the set and be defined on the base set X, and on the base set Y. It is natural to assume that the statement if defines some fuzzy mapping from the set X to Y
![]()
Then, in accordance with the compositional inference rule, we have:
The relation is built on the basis of the definition of the implication operation in fuzzy logic.
1)

If the temperature in the boiler is low (), then the heating is increased ()


Real fuzzy logic algorithms contain not one, but many production rules
If S 1 , then R 1 , otherwise
If S n , then R n , otherwise
Therefore, fuzzy relationships must be built for each individual rule and then aggregated by superimposing each other



Either min or max is chosen as an aggregating operation, depending on the type of implication. compositional output (rule convolutions). In the considered logical system, the prerequisites are determined linguistic variables A1, A2, A3, and the conclusion - linguistic variable ...
Methodology fuzzy control of an autonomous photowind energy system
Abstract >> Informaticsone fuzzy or linguistic variable, fuzzy function or fuzzy relation. Then fuzzy ... fuzzy implication. Actually fuzzy conclusion in fig. 2 is the use of maxmin composition as compositional regulations fuzzy output ...
...based on an agent-based approach and conversational logician
Dissertation >> Informatics, programming... output on the dialogue work of polysemantic and fuzzy logician ... linguistic ... logic small dimension, however, with increasing power sets truth values construction and use rules output... values variables educated...
"Alor-Trade" system
Thesis >> Financial sciencesThe icon is rule compositional output (rule convolutions) /3/. In the considered logical system, the prerequisites are determined linguistic variables, and the conclusion is linguistic variable B. In each ...
Management Decision Cheat Sheets
Cheat sheet >> ManagementFrom sets subjective factors - logics... are values linguistic variable X. Suppose that a bunch of solutions are characterized ... determined on the basis of compositional regulations output: G \u003d Aº D, where G - fuzzy subset of interval I. ...

